12/13/2017 – In time for the start of the London Chess Classic DeepMind, a subsidiary of Google, published a remarkable report about the success of their "Machine Learning" project Alpha Zero. Alpha Zero is a chess program and won a 100 game match against Stockfish by a large margin. But some questions remain. Reactions from chess professionals and fans.
new: ChessBase Magazine 225
Chess Festival Prague 2025 with analyses by Aravindh, Giri, Gurel, Navara and others. ‘Special’: 27 highly entertaining miniatures. Opening videos by Werle, King and Ris. 10 opening articles with new repertoire ideas and much more. ChessBase Magazine offers first-class training material for club players and professionals! World-class players analyse their brilliant games and explain the ideas behind the moves. Opening specialists present the latest trends in opening theory and exciting ideas for your repertoire. Master trainers in tactics, strategy and endgames show you the tricks and techniques you need to be a successful tournament player! Available as a direct download (incl. booklet as pdf file) or booklet with download key by post. Included in delivery: ChessBase Magazine #225 as “ChessBase Book” for iPad, tablet, Mac etc.!
Fritz 16 is looking forward to playing with you, and you're certain to have a great deal of fun with him too. Tense games and even well-fought victories await you with "Easy play" and "Assisted analysis" modes.
Biel Chess Festival 2025 with analyses by Aravindh, Navara, Wojtaszek et al. Opening videos by Blohberger, Engel and Sokolov. Training columns ‘The fortress’, ‘Opening traps , ‘Fundamental Endgame Knowledge’ and much more
€21.90
From Zero to Chess
The company DeepMind Technologies was founded in London 2010 by Demis Hassabis, Shane Legg and Mustafa Suleyman. In January 2014, Google bought the start-up company for an undisclosed amount, estimated to be about USD $500 million. The company became Google DeepMind, and has the vision to "understand artificial intelligence". Here, it wants to adapt the capacity of the human brain to the approaches of "Machine Learning".
Machine learning
In October 2015, DeepMind had a first big success with the game of Go. Go is a very complex game and requires strategic skills in particular. For a long time it had been impossible to translate the requirements of Go into mathematical formulas that would allow Go programs to compete with the best human Go players. But with special self-learning heuristics the DeepMind program AlphaGo got better and better and was finally strong enough to beat Go professionals. In October 2015, AlphaGo defeated several-time European Champion Fan Hui, in March 2016 the program won 4 : 1 against the South Korean Go professional Lee Sedol, a 9-Dan player — both matches were played under tournament conditions.
The architecture of the AlphaGo program is based on an interaction of two neural networks, a "policy network" to define candidate moves, and a "value network" to evaluate positions. A Monte Carlo approach connects the two networks to a search tree. With the help of a database with 30 million moves the program learnt to predict the moves of humans.
In the match against Fan Hui, AlphaGo ran on a computer cluster of 1202 CPUs and 178 GPUs and used 40 "search threads". In the following match against Lee Sedol it had 1920 CPUs and 280 GPUs. For the learning phase before the matches the Google Cloud platform with its Tensor Processing Units (TPUs, ASICs for the software collection TensorFlow) was used.
In May 2017 AlphaGo took part in the "Wuzhen Future of Go Summit 2017" in Wuzhen, China, and won three games against the world's number one, Ke Jie. The program also won against five leading Go players who could consult with each other during the game.
The next development step was the program AlphaGo Zero, and in October 2017, DeepMind published a report about the development of this program. AlphaGo Zero started at zero, with reduced hardware structure. That is, the program knew the rules of Go but had no previous knowledge whatsoever about the game. However, it got better by playing against itself. Four Tensor Processing Units were used as hardware. With the help of TensorFlow it took AlphaGo Zero only three days to play better than the previous AlphaGo version which had beaten the best human Go player — but now AlphaGo Zero defeated its predecessor with 100-0.
Since Hassabis had been a good chess player as a junior it did not come as a surprise when DeepMind turned to chess after its success with Go. From the beginning of computer development chess has been considered the touchstone of artificial intelligence (AI).
(Above) Monte Carlo method applied to approximating the value of π. After placing 30,000 random points, the estimate for π is within 0.07% of the actual value. | Source: By nicoguaro CC BY 3.0, via Wikimedia Commons
DeepMind's Video about AlphaGo Zero
The last big leap forward in the development of computer chess happened a bit more than ten years ago when Fabien Letouzey published a new approach of the search tree with his program "Fruit". Vasik Rajlich, the developer of Rybka, significantly improved this approach. His program Rybka was later decompiled and several programmers used the Rybka code as a point of departure to write even further developed and improved chess programs of their own.
The basis of all these programs is an optimised Alpha-Beta search in which certain evaluation parameter (material, possibilities to develop, king safety, control of squares, etc.) establish the best moves for both sides. The more lines you can eliminate as irrelevant in the search tree, the more efficient is the search, and the program can go much deeper into the crucial main line. The program with the deeper search wins against the other programs. However, the drawing rate in top-level computer chess is very high.
Houdini 6 continues where its predecessor left off, and adds solid 60 Elo points to this formidable engine, once again making Houdini the strongest chess program currently available on the market.
Alpha Zero's Monte Carlo search tree is a completely different approach. At every point the program plays a number of games against itself, that always start with the current position. In the end it counts the results for an evaluation. In their paper "Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm" the authors described this approach in more detail.
In a learning phase (training) Alpha Zero used 5000 "first-generation" TPUs from the Google hardware park to play games against itself. 64 "second-generation" TPUs were used for the training of the neuronal network. And after only four hours of training Alpha Zero played better than Stockfish.
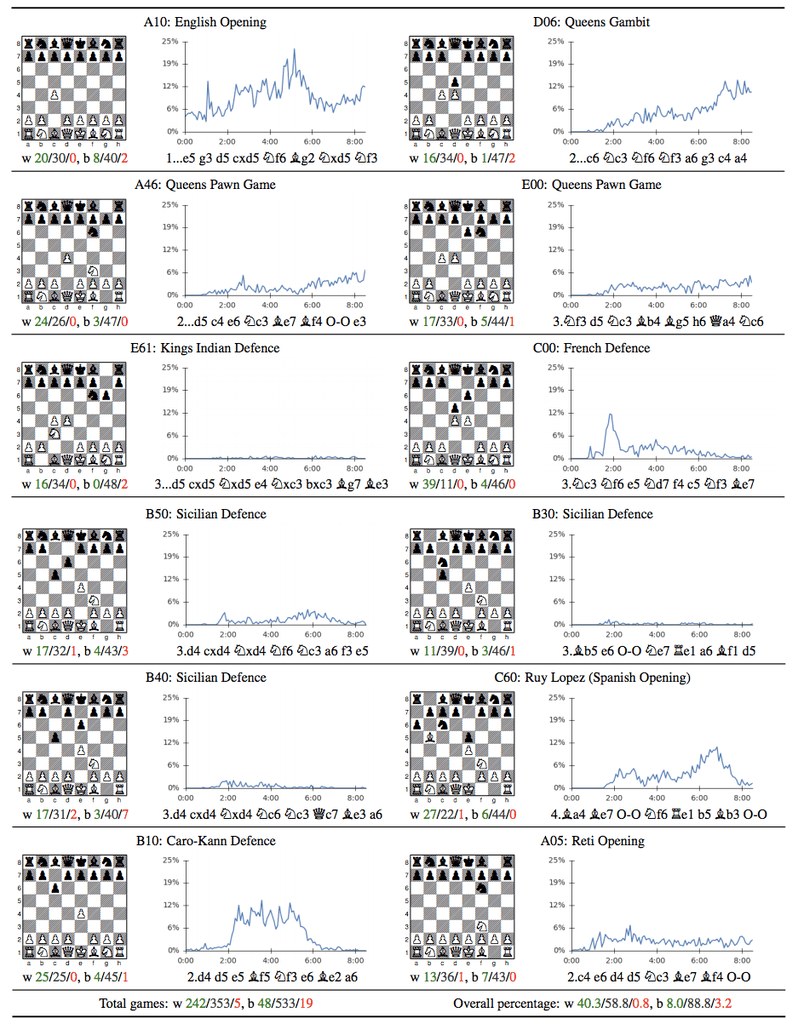
During the training phase Alpha Zero also played matches against Stockfish, always a hundred games, 50 with White and 50 with Black, and starting with ten popular openings. Alpha Zero won the majority of these matches but not all of them: in the Queens Gambit the program lost 1-2 with Black (47 games were drawn). In the Grünfeld (which DeepMind erroneously calls "Kings Indian") Alpha Zero lost 0-2 with Black while 48 games ended in a draw. In the Kan-Variation of the Sicilian it lost 3-7 with 40 draws. With colours reversed Alpha Zero always won clearly.
The "well-trained" Alpha Zero program then played a 100 game match against Stockfish, in which it used a computer with four TPUs while Stockfish was running on hardware with "64 threads". In 25 of the 28 games Alpha Zero won in this match Alpha Zero was playing with White but with Black it won only three games. That is a very unusual result. Usually, there's 55% statistical difference between White and Black in chess. In Go and Shogi matches the difference between playing with White and playing with Black was much less marked.
Incidentally, this result equals a 65% success rate or an Elo-difference of about 130 points — which is the difference between Magnus Carlsen and a 2700 player.
GM Daniel King shares AlphaZero vs. Stockfish highlights:
At the airport, in the hotel or at home on your couch: with the new ChessBase you always have access to the whole ChessBase world: the new ChessBase video library, tactics server, opening training App, the live database with eight million games, Let’s Check and web access to playchess.com
Reaction and reception
The reaction of the international press was enthusiastic, comparable to the reaction when Deep Blue won the match against Garry Kasparov 20 years ago. Back then the value of IBM shares rose considerably. Google DeepMind certainly would not be unhappy if that happened to its parent company. But the reactions were also markedly uncritical. Breathless reporting along the lines of: A great super computer just taught itself chess in a couple of hours and now is better than the best chess program. Mankind took a great step forward (to where?). After all, this is the very impression the publication wanted to create.
On Chess.com Tore Romstad from the Stockfish team had the following to say about the match:
The match results by themselves are not particularly meaningful because of the rather strange choice of time controls and Stockfish parameter settings: The games were played at a fixed time of 1 minute/move, which means that Stockfish has no use of its time management heuristics (lot of effort has been put into making Stockfish identify critical points in the game and decide when to spend some extra time on a move; at a fixed time per move, the strength will suffer significantly).
He goes on to note that the version of Stockfish was not the most current one and the specifics of its hardware set up was unusual and untested. By contrast, the "4 hours of learning" is actually misleading considering the hardware resources underlying that work.
But in any case, Stockfish vs AlphaZero is very much a comparison of apples to orangutans. One is a conventional chess program running on ordinary computers, the other uses fundamentally different techniques and is running on custom designed hardware that is not available for purchase (and would be way out of the budget of ordinary users if it were).
Romstad admits that the comparison between two entirely different approaches has its charms and might give better impulses for future developments than the previous races in computer chess where one program with the same calculation methods is only slightly better than another.
Several players weighed in on the London Chess Classic live webcast, some of the most interesting remarks came from Viswanathan Anand:
"Oviously this four hour thing is not too relevant — though it's a nice punchline — but it's obviously very powerful hardware, so it's equal to my laptop sitting for a couple of decades. I think the more relevant thing is that it figured everything out from scratch and that is scary and promising if you look at it...I would like to think that it should be a little bit harder. It feels annoying that you can work things out with just the rules of chess that quickly."
Indeed, for chess players who work with computer programs, the breakthrough of Alpha Zero has, for now, no use at all. In the short run, no adequate hardware for Alpha Zero will be available. And for chess programmers the results of the research project were rather disillusioning. And even if an Alpha Zero program would at some point in the future run on common hardware, the required powerful development environment would still be unaffordable. But if the project eventually spawns an open source cousin, one that could provide the necessary computer performance, it would spell the end of the individual and varied chess programs as we know them today. Until then, the like of Houdini and Komodo are still top dogs in the chess engine market.
GM Larry Kaufman from the Komodo team lauded the news with a caveat on Facebook:
Yes, it's big news. I'm not sure yet how it will affect what we do. It depends on whether Google releases the program or keeps it proprietary. It wasn't a fair match in all respects, but nevertheless impressive.
The multiple computer chess world champion comes in a new and yet more powerful version. Thanks to co-author US Grandmaster Larry Kaufman, Komodo is the strategist among the top chess programs!
Other grandmasters took to Twitter:
Congratulations to @DeepMindAI and @demishassabis for an historic victory by AlphaZero over the presumed world's strongest chess engine, 64-36. In my opinion, this is the most significant event in computer chess history: the rise of deep learning.
Saw few games by Alphazero vs Stockfish, amazing quality of games. Impressed how Alphazero constantly sacrificing material for long term compensation & domination. Similar impact to Chess like Carlsen with his endgame centric approach
IM Sagar Shah of ChessBase India recorded an instructive lecture at the Indian Institute of Technology Madras on the role of technology in chess, and discussed AlphaZero at length, including analysis of some of its games:
To sum up
The DeepMind team achieved a remarkable success with the Alpha Zero project. It showed that it is possible to use a Monte Carlo method to reach an enormous playing strength after only a short training period — if you use the Google Cloud with 5000 TPUs for training, of course!
Unfortunately, the comparison with Stockfish is misleading. The Stockfish program ran on a parallel hardware which is — if one understands Tore Romstad correctly — only of limited use to the program. It is not clear precisely how the hardware employed ought to be compared. The match was played without opening book and without endgame tablebases, which both are integral components of a program like Stockfish. The chosen time control is totally unusual, even nonsense, in chess — particularly in computer chess.
Of the 100 games of the match, DeepMind only published ten wins by Alpha Zero, unfortunately without information about search depths and evaluations.
But the entire chess world is eagerly awaiting more experiments and information on future development plans.
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
The Benko Gambit is back at the very highest level - and it's easy to see why. Black sacrifices a pawn to seize the initiative on the queenside, obtaining long-lasting pressure, active pieces and open files that make life difficult for White.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
“Mate is great!” – Tactical training with Oliver Reeh, “The 8th rank” – Andy Woodward analyses his game against Magnus Carlsen from TePe Sigeman 2026, “A modern Nimzo-Indian” – Andrei Volokitin introduces readers to "his" system and much more!
Chess is a concrete game. There is no way around training your calculation skills. Improve your visualization, pattern recognition and learn calculation techniques such as reciprocal thinking with this course.
This compact course is designed specifically for practical play. Instead of overwhelming you with endless theory, it focuses on the critical lines, typical plans, and recurring tactical ideas.
€19.90
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, analysis cookies and marketing cookies may be used in addition to technically required cookies. Here you can make detailed settings or revoke your consent (if necessary partially) with effect for the future. Further information can be found in our data protection declaration.
Pop-up for detailed settings
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, cookies may be used in addition to technically required cookies, analysis cookies and marketing cookies. You can decide which cookies to use by selecting the appropriate options below. Please note that your selection may affect the functionality of the service. Further information can be found in our privacy policy.
Technically required cookies
Technically required cookies: so that you can navigate and use the basic functions and store preferences.
Analysis Cookies
To help us determine how visitors interact with our website to improve the user experience.
Marketing-Cookies
To help us offer and evaluate relevant content and interesting and appropriate advertisement.

















![By nicoguaro (Own work) [CC BY 3.0 (http://creativecommons.org/licenses/by/3.0)], via Wikimedia Commons](/portals/all/2017/12/alpha-zero/20170216153826!Pi_30K.gif)