12/6/2017 – Imagine this: you tell a computer system how the pieces move — nothing more. Then you tell it to learn to play the game. And a day later — yes, just 24 hours — it has figured it out to the level that beats the strongest programs in the world convincingly! DeepMind, the company that recently created the strongest Go program in the world, turned its attention to chess, and came up with this spectacular result.
new: ChessBase Magazine 225
Chess Festival Prague 2025 with analyses by Aravindh, Giri, Gurel, Navara and others. ‘Special’: 27 highly entertaining miniatures. Opening videos by Werle, King and Ris. 10 opening articles with new repertoire ideas and much more. ChessBase Magazine offers first-class training material for club players and professionals! World-class players analyse their brilliant games and explain the ideas behind the moves. Opening specialists present the latest trends in opening theory and exciting ideas for your repertoire. Master trainers in tactics, strategy and endgames show you the tricks and techniques you need to be a successful tournament player! Available as a direct download (incl. booklet as pdf file) or booklet with download key by post. Included in delivery: ChessBase Magazine #225 as “ChessBase Book” for iPad, tablet, Mac etc.!
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before. FRITZ is more than just a chess engine – it’s a training revolution! Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
€49.90
DeepMind and AlphaZero
About three years ago, DeepMind, a company owned by Google that specializes in AI development, turned its attention to the ancient game of Go. Go had been the one game that had eluded all computer efforts to become world class, and even up until the announcement was deemed a goal that would not be attained for another decade! This was how large the difference was. When a public challenge and match was organized against the legendary player Lee Sedol, a South Korean whose track record had him in the ranks of the greatest ever, everyone thought it would be an interesting spectacle, but a certain win by the human. The question wasn’t even whether the program AlphaGo would win or lose, but how much closer it was to the Holy Grail goal. The result was a crushing 4-1 victory, and a revolution in the Go world. In spite of a ton of second-guessing by the elite, who could not accept the loss, eventually they came to terms with the reality of AlphaGo, a machine that was among the very best, albeit not unbeatable. It had lost a game after all.
The saga did not end there. A year later a new updated version of AlphaGo was pitted against the world number one of Go, Ke Jie, a young Chinese whose genius is not without parallels to Magnus Carlsen in chess. At the age of just 16 he won his first world title and by the age of 17 was the clear world number one. That had been in 2015, and now at age 19, he was even stronger. The new match was held in China itself, and even Ke Jie knew he was most likely a serious underdog. There were no illusions anymore. He played superbly but still lost by a perfect 3-0, a testimony to the amazing capabilities of the new AI.
Many chess players and pundits had wondered how it would do in the noble game of chess. There were serious doubts on just how successful it might be. Go is a huge and long game with a 19x19 grid, in which all pieces are the same, and not one moves. Calculating ahead as in chess is an exercise in futility so pattern recognition is king. Chess is very different. There is no questioning the value of knowledge and pattern recognition in chess, but the royal game is supremely tactical and a lot of knowledge can be compensated for by simply outcalculating the opponent. This has been true not only of computer chess, but humans as well.
However, there were some very startling results in the last few months that need to be understood. DeepMind’s interest in Go did not end with that match against the number one. You might ask yourself what more there was to do after that? Beat him 20-0 and not just 3-0? No, of course not. However, the super Go program became an internal litmus test of a sorts. Its standard was unquestioned and quantified, so if one wanted to test a new self-learning AI, and how good it was, then throwing it at Go and seeing how it compared to the AlphaGo program would be a way to measure it.
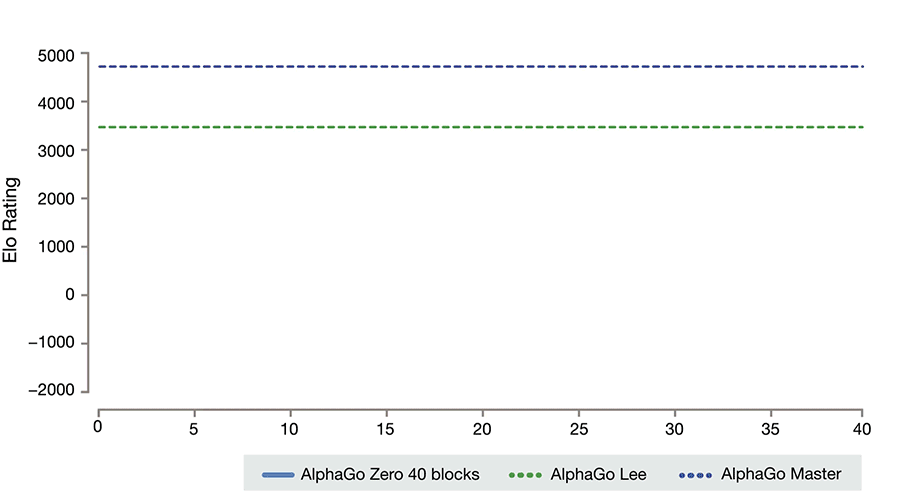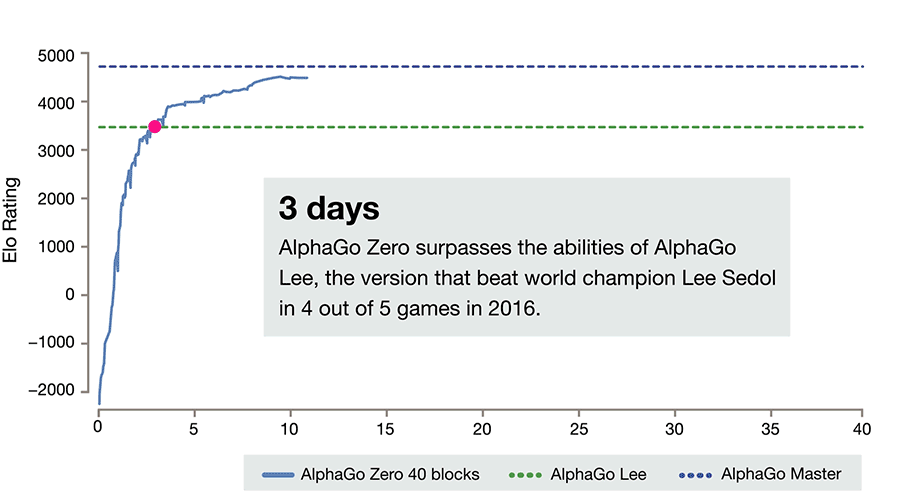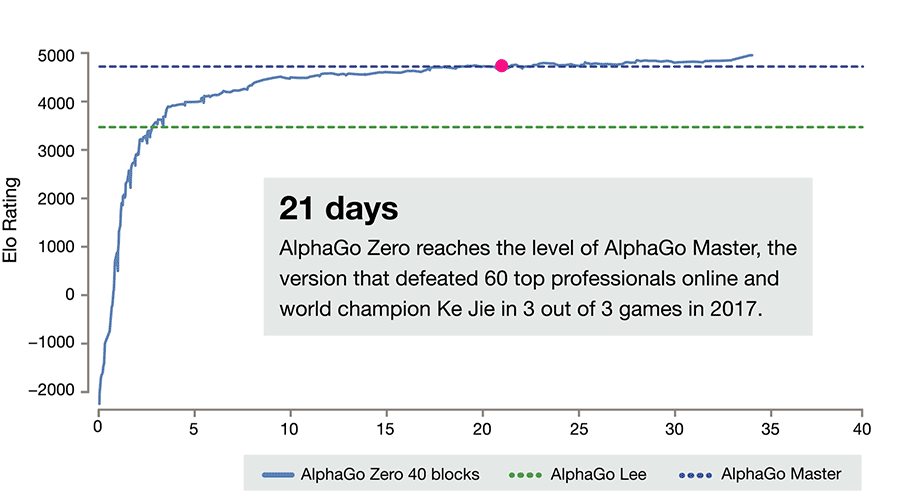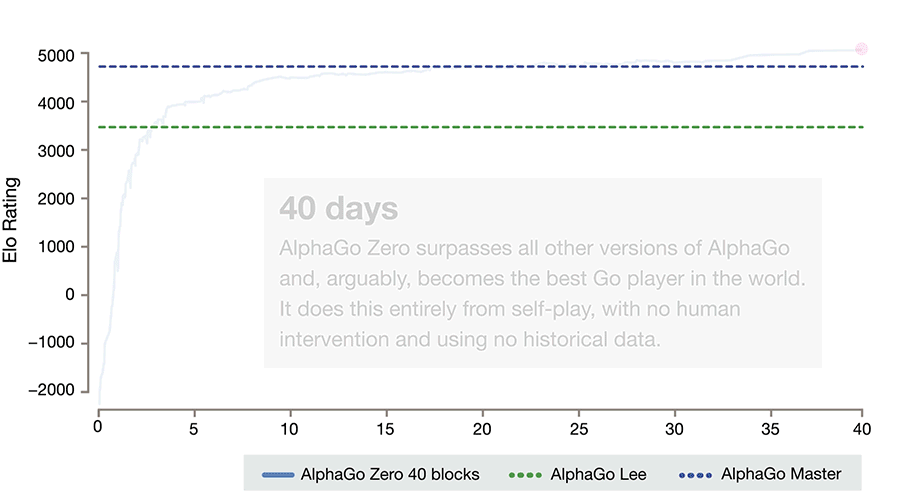
A new AI was created called AlphaZero. It had several strikingly different changes. The first was that it was not shown tens of thousands of master games in Go to learn from, instead it was shown none. Not a single one. It was merely shown the rules, without any other information. The result was a shock. Within just three days its completely self-taught Go program was stronger than the version that had beat Lee Sedol, a result the previous AI had needed over a year to achieve. Within three weeks it was beating the strongest AlphaGo that had defeated Ke Jie. What is more: while the Lee Sedol version had used 48 highly specialized processors to create the program, this new version used only four!
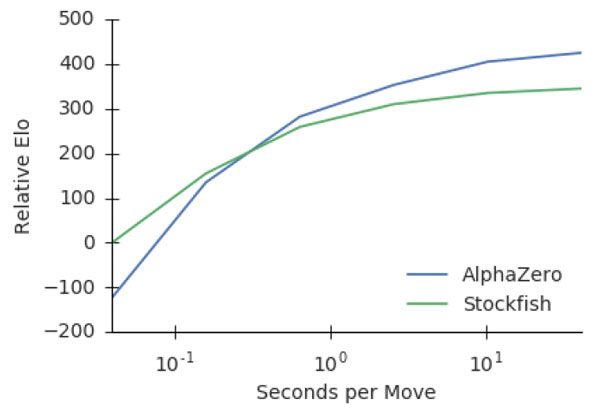
Graph showing the relative evolution of AlphaZero : Source: DeepMind
AlphaZero learns Chess
Approaching chess might still seem unusual. After all, although DeepMind had already shown near revolutionary breakthroughs thanks to Go, that had been a game that had yet to be ‘solved’. Chess already had its Deep Blue 20 years ago, and today even a good smartphone can beat the world number one. What is there to prove exactly?
Garry Kasparov is seen chatting with Demis Hassabis, founder of DeepMind | Photo: Lennart Ootes
It needs to be remembered that Demis Hassabis, the founder of DeepMind has a profound chess connection of his own. He had been a chess prodigy in his own right, and at age 13 was the second highest rated player under 14 in the world, second only to Judit Polgar. He eventually left the chess track to pursue other things, like founding his own PC video game company at age 17, but the link is there. There was still a burning question on everyone’s mind: just how well would AlphaZero do if it was focused on chess? Would it just be very smart, but smashed by the number-crunching engines of today where a single ply is often the difference between winning or losing? Or would something special come of it?
Professor David Silver explains how AlphaZero was able to progress much quicker when it had to learn everything on its own as opposed to analzying large amounts of data. The efficiency of a principled algorithm was the most important factor.
A new paradigm
On December 5 the DeepMind group published a new paper at the site of Cornell University called "Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm", and the results were nothing short of staggering. AlphaZero had done more than just master the game, it had attained new heights in ways considered inconceivable. The test is in the pudding of course, so before going into some of the fascinating nitty-gritty details, let’s cut to the chase. It played a match against the latest and greatest version of Stockfish, and won by an incredible score of 64 : 36, and not only that, AlphaZero had zero losses (28 wins and 72 draws)!
Stockfish needs no introduction to ChessBase readers, but it's worth noting that the program was on a computer that was running nearly 900 times faster! Indeed, AlphaZero was calculating roughly 80 thousand positions per second, while Stockfish, running on a PC with 64 threads (likely a 32-core machine) was running at 70 million positions per second. To better understand how big a deficit that is, if another version of Stockfish were to run 900 times slower, this would be equivalent to roughly 8 moves less deep. How is this possible?
“AlphaZero compensates for the lower number of evaluations by using its deep neural network to focus much more selectively on the most promising variations – arguably a more “human-like” approach to search, as originally proposed by Shannon. Figure 2 shows the scalability of each player with respect to thinking time, measured on an Elo scale, relative to Stockfish or Elmo with 40ms thinking time. AlphaZero’s MCTS scaled more effectively with thinking time than either Stockfish or Elmo, calling into question the widely held belief that alpha-beta search is inherently superior in these domains.”
This diagram shows that the longer AlphaZero had to think, the more it improved compared to Stockfish
In other words, instead of a hybrid brute-force approach, which has been the core of chess engines today, it went in a completely different direction, opting for an extremely selective search that emulates how humans think. A top player may be able to outcalculate a weaker player in both consistency and depth, but it still remains a joke compared to what even the weakest computer programs are doing. It is the human’s sheer knowledge and ability to filter out so many moves that allows them to reach the standard they do. Remember that although Garry Kasparov lost to Deep Blue it is not clear at all that it was genuinely stronger than him even then, and this was despite reaching speeds of 200 million positions per second. If AlphaZero is really able to use its understanding to not only compensate 900 times fewer moves, but surpass them, then we are looking at a major paradigm shift.
How does it play?
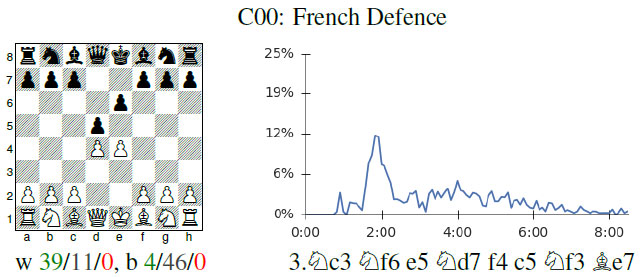
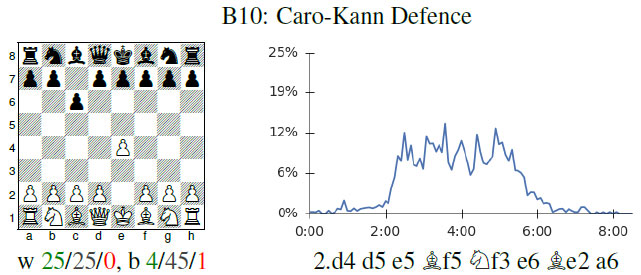
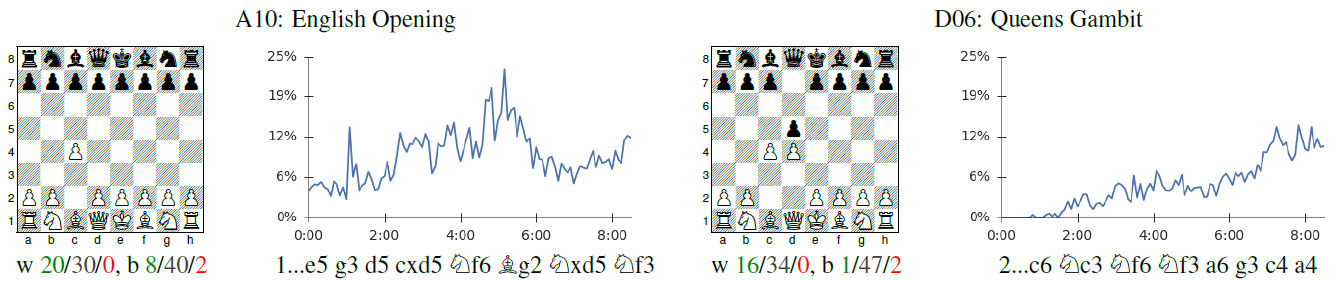
Since AlphaZero did not benefit from any chess knowledge, which means no games or opening theory, it also means it had to discover opening theory on its own. And do recall that this is the result of only 24 hours of self-learning. The team produced fascinating graphs showing the openings it discovered as well as the ones it gradually rejected as it grew stronger!
Professor David Silver, lead scientist behind AlphaZero, explains how AlphaZero learned openings in Go, and gradually began to discard some in favor of others as it improved. The same is seen in chess.
In the diagram above, we can see that in the early games, AlphaZero was quite enthusiastic about playing the French Defense, but after two hours (this so humiliating) began to play it less and less.
The Caro-Kann fared a good deal better, and held a prime spot in AlphaZero's opening choices until it also gradually filtered it out. So what openings did AlphaZero actually like or choose by the end of its learning process? The English Opening and the Queen's Gambit!
The paper also came accompanied by ten games to share the results. It needs to be said that these are very different from the usual fare of engine games. If Karpov had been a chess engine, he might have been called AlphaZero. There is a relentless positional boa constrictor approach that is simply unheard of. Modern chess engines are focused on activity, and have special safeguards to avoid blocked positions as they have no understanding of them and often find themselves in a dead end before they realize it. AlphaZero has no such prejudices or issues, and seems to thrive on snuffing out the opponent’s play. It is singularly impressive, and what is astonishing is how it is able to also find tactics that the engines seem blind to.
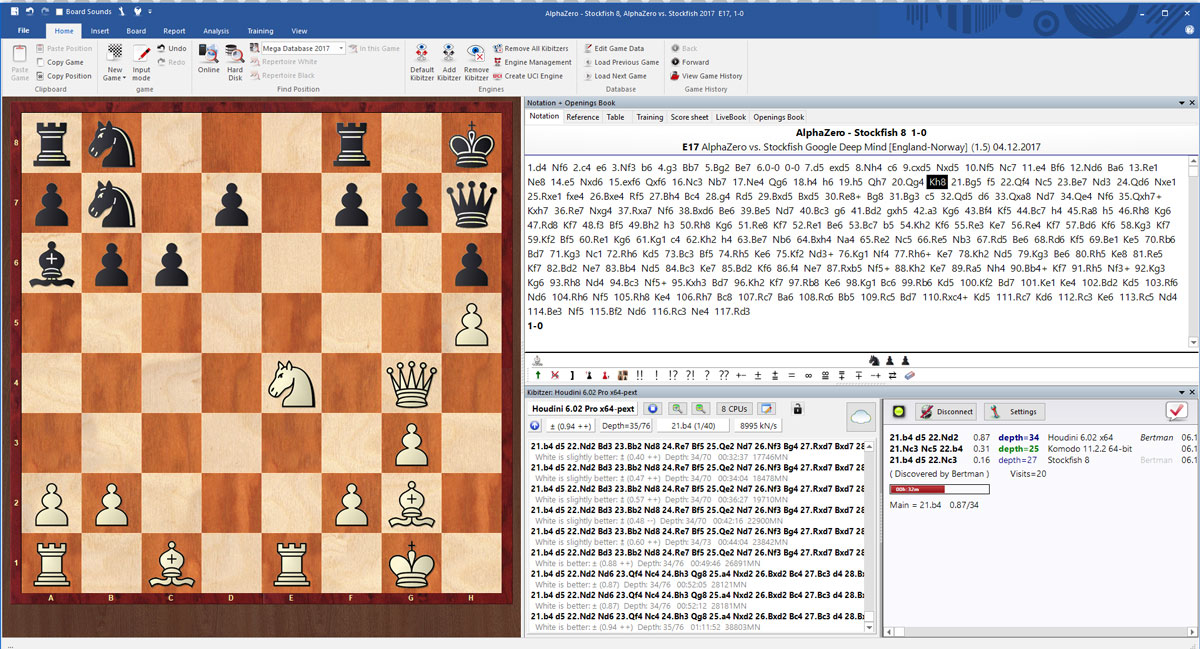
In this position from Game 5 of the ten published, this position arose after move 20...Kh8. The completely disjointed array of Black’s pieces is striking, and AlphaZero came up with the fantastic 21.Bg5!! After analyzing it and the consequences, there is no question this is the killer move here, and while my laptop cannot produce 70 million positions per second, I gave it to Houdini 6.02 with 9 million positions per second. It analyzed it for one full hour and was unable to find 21.Bg5!!
A screenshot of Houdini 6.02 after an hour of analysis
Here is another little gem of a shot, in which AlphaZero had completely stymied Stockfish positionally, and now wraps it up with some nice tactics. Look at this incredible sequence in game nine:
Here AlphaZero played the breathtaking 30. Bxg6!! The threat is obviously 30...fxg6 31. Qxe6+, but how do you continue after the game's 30...Bxg5 31. Qxg5 fxg6?
Here AlphaZero continued with 32. f5!! and after 32...Rg8 33. Qh6 Qf7 34. f6 obtained a deadly bind, and worked it into a win 20 moves later. Time to get a thesaurus for all the references synonymous of 'amazing'.
What lies ahead
So where does this leave chess, and what does it mean in general? This is a game-changer, a term that is so often used and abused, and there is no other way of describing it. Deep Blue was a breakthrough moment, but its result was thanks to highly specialized hardware whose purpose was to play chess, nothing else. If one had tried to make it play Go, for example, it would have never worked. This completely open-ended AI able to learn from the least amount of information and take this to levels hitherto never imagined is not a threat to ‘beat’ us at any number of activities, it is a promise to analyze problems such as disease, famine, and other problems in ways that might conceivably lead to genuine solutions.
For chess, this will likely lead to genuinely breakthrough engines following in these footsteps. That is what happened in Go. For years and years, Go programs had been more or less stuck where they were, unable to make any meaningful advances, and then came along AlphaGo. It wasn't because AlphaGo offered some inspiration to 'try harder', it was because just as here, a paper was published detailing all the techniques and algorithms developed and used so that others might follow in their footsteps. And they did. Literally within a couple of months, new versions of top programs such as Crazy Stone, began offering updated engines with Deep Learning, which brought hundreds (plural) of Elo in improvement. This is no exaggeration.
Within a couple of months, the revolutionary techniques used to create AlphaGo began to appear in top PC programs of Go
The paper on chess offers similar information allowing anyone to do what they did. Obviously they won't have the benefit of the specialized TPUs, a processor designed especially for this deep learning training, but nor are they required to do so. It bears remembering that this was also done without the benefit of many of the specialized programming techniques and tricks in chess programming. Who is to say they cannot be combined for even greater results? Even the DeepMind team think it bears investigating:
"It is likely that some of these techniques could further improve the performance of AlphaZero; however, we have focused on a pure self-play reinforcement learning approach and leave these extensions for future research."
Replay the ten games between AlphaZero and Stockfish 8 (70 million NPS)
Albert SilverBorn in the US, he grew up in Paris, France, and after college moved to Rio de Janeiro, Brazil. He had a peak rating of 2240 FIDE, and was a key designer of Chess Assistant 6. In 2010 he joined the ChessBase family as an editor and writer at ChessBase News. He is also a passionate photographer with work appearing in numerous publications, and the content creator of the YouTube channel, Chess & Tech as well as the author of Typing Tomes, a powerful typing program.
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
The Benko Gambit is back at the very highest level - and it's easy to see why. Black sacrifices a pawn to seize the initiative on the queenside, obtaining long-lasting pressure, active pieces and open files that make life difficult for White.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
“Mate is great!” – Tactical training with Oliver Reeh, “The 8th rank” – Andy Woodward analyses his game against Magnus Carlsen from TePe Sigeman 2026, “A modern Nimzo-Indian” – Andrei Volokitin introduces readers to "his" system and much more!
Chess is a concrete game. There is no way around training your calculation skills. Improve your visualization, pattern recognition and learn calculation techniques such as reciprocal thinking with this course.
This compact course is designed specifically for practical play. Instead of overwhelming you with endless theory, it focuses on the critical lines, typical plans, and recurring tactical ideas.
€19.90
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, analysis cookies and marketing cookies may be used in addition to technically required cookies. Here you can make detailed settings or revoke your consent (if necessary partially) with effect for the future. Further information can be found in our data protection declaration.
Pop-up for detailed settings
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, cookies may be used in addition to technically required cookies, analysis cookies and marketing cookies. You can decide which cookies to use by selecting the appropriate options below. Please note that your selection may affect the functionality of the service. Further information can be found in our privacy policy.
Technically required cookies
Technically required cookies: so that you can navigate and use the basic functions and store preferences.
Analysis Cookies
To help us determine how visitors interact with our website to improve the user experience.
Marketing-Cookies
To help us offer and evaluate relevant content and interesting and appropriate advertisement.