3/13/2016 – It was history in the making, and considerably sooner than anyone expected, whether players or programmers. AlphaGo, the Go program by DeepMind, has effectively won a five-game match after a 3-0 start against one of the world’s best players, Lee Sedol. The match will be played out to the end, and in the meantime here is a look at the match, AlphaGo, and what makes it so special.
new: Fritz 20
Your personal chess trainer. Your toughest opponent. Your strongest ally. FRITZ 20 is more than just a chess engine – it is a training revolution for ambitious players and professionals. Whether you are taking your first steps into the world of serious chess training, or already playing at tournament level, FRITZ 20 will help you train more efficiently, intelligently and individually than ever before.
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before. FRITZ is more than just a chess engine – it’s a training revolution! Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
FIDE World Cup 2025 with analyses by Adams, Bluebaum, Donchenko, Shankland, Wei Yi and many more. Opening videos by Blohberger, King and Marin. 11 exciting opening articles with new repertoire ideas and much more.
€21.90
History in the making
In order to appreciate just how extraordinary an achievement AlphaGo is, a comparison with chess programs, which have been punishing the elite for decades now, is in order. What is so special or different about Go that somehow resisted programming efforts and genius for so long?
What is Go
Woman Playing Go (Tang Dynasty c. 744)
Go, which translates to “encircling game” is a game whose roots and history easily rival those of chess, with written records going back to the 4th century BC. It is played on a 19 x 19 grid, with each player placing stones on the board. Black moves first, and then white, with the pieces never moving from their squares, though they can be removed if captured. The goal, as the translation of its name implies, is to have surrounded a larger total area of the board with one's stones than the opponent by the end of the game.
Korean couple, in traditional dress, play in a photograph dated between 1910 and 1920
This ultra-simplified introduction to Go is necessary to understand the complexities and challenges involved in programming it, compared to a game such as chess. Chess programming is dominated by the search and the evaluation function. The evaluation starts with the most fundamental aspect: the differing values of the pieces, while the search is about pruning down the number of moves to calculate and then looking ahead as many moves as possible to reach a quality decision. In Go, both of these are instantly problematic.
Comparing Go and chess programming
The search function in chess engines boils down to selecting a number of moves and steadily looking deeper and deeper. At the beginning of a chess game, White has twenty possible moves. After that, Black also has twenty possible moves. Once both sides have played, there are 400 possible board positions. Go, by contrast, begins with an empty board, where Black has 361 possible opening moves, one at every intersection of the 19 by 19 grid. White can follow with 360 moves. That makes for 129,960 possible board positions after just the first round of moves. It is easy to see that even with the most severe pruning techniques, a program would only be able to see ahead a few moves at best. However, the situation is even worse than that, since while the average chess game is roughly 60-80 moves (white moves and black moves), the average game of Go lasts 200-240 moves.
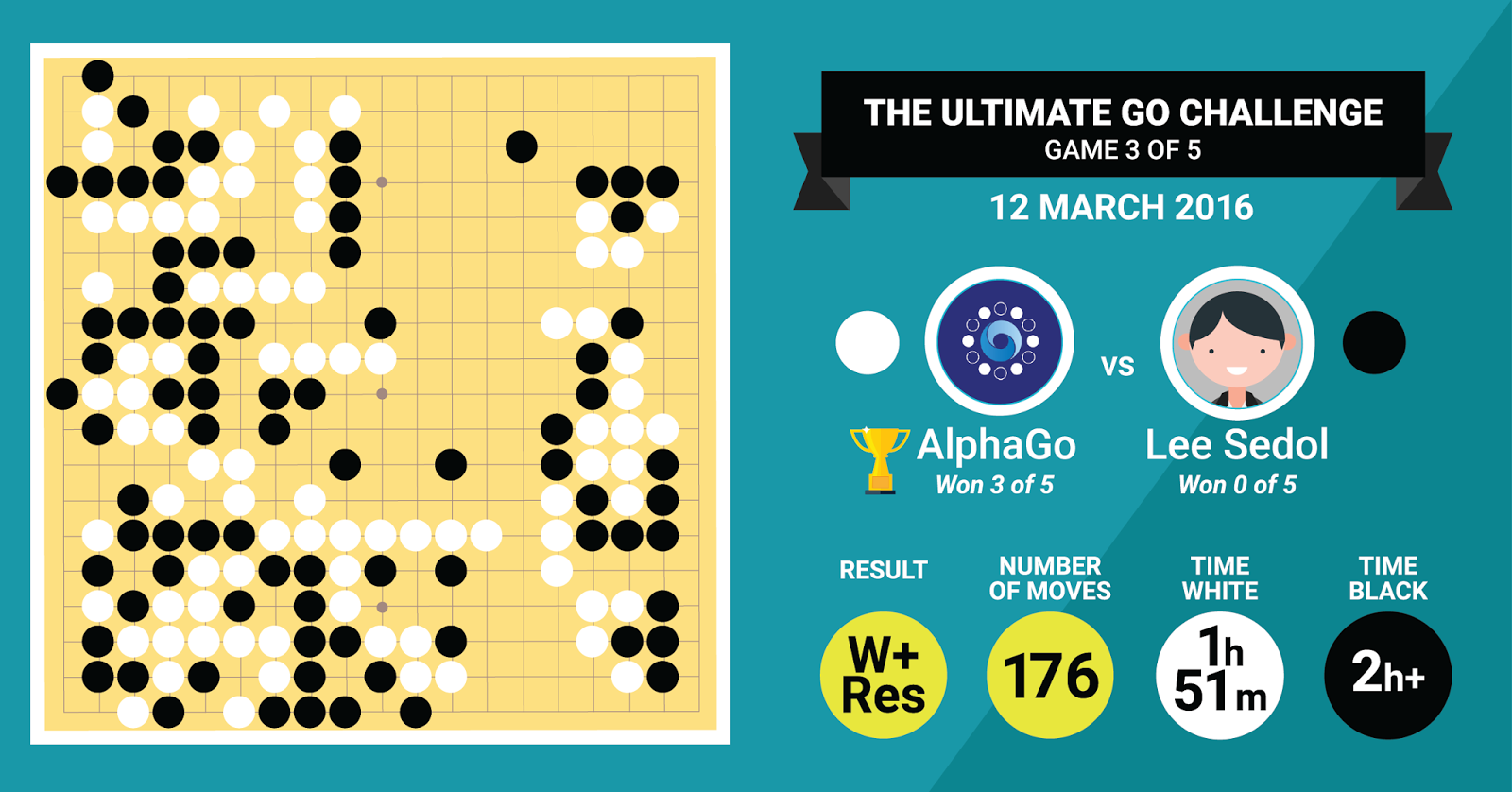
An overview of the third game from AlphaGo vs Lee Sedol. White won it via resignation,
hence the W+Res in the result space after 176 moves
Next comes the evaluation function, or determining what constitutes a bad position or a good position, to choose between moves. In chess this starts with the value of the pieces, where the king is priceless (capture it and win), the queen is worth nine pawns, a rook is five, and so on. This is then tempered by various well-defined aspects such as isolated pawns, centralized knights, and so forth. Go begins with no difference in value of any of its pieces, and the board situations are so large and complex that simple rules such as a doubled-pawn make no sense. Now that you understand why chess programming strategies have failed so abysmally in Go, what is the solution?
For a long time, there was none really, and as a result, until 2005-2006, the best programs in the world were weak amateurs at best, equivalent to a 1400-1600 player in chess. The comparison in levels in chess and Go is difficult due to the range of levels in Go, but that will be the topic of the final article on the match. Don’t think for an instant this was due to a lack of resources invested, since the promised payback was huge: tens of millions of Go players in East Asia who would line up to buy a strong program.
The Monte Carlo Tree Search revolution
The change came with the French programmer Rémi Coulom. Coulom was a programming prodigy who at the age of ten, less than a year after receiving his first computer, had programmed Mastermind. In four years, he had created an AI that could play Connect Four. Othello followed shortly thereafter, and by 18, Coulom had written his first chess program. The Frenchman eventually earned a PhD for work on how neural networks and reinforcement learning can be used to train simulated robots to swim.
Coulom had exchanged ideas with a fellow academic named Bruno Bouzy, who believed that the secret to computer Go might lie in a search algorithm known as Monte Carlo. Rather than having to search every branch of the game tree, Monte Carlo would play out a series of random games from each possible move, and then deduce the value of the move from an analysis of the results.
While Bouzy was unable to make the idea work, Coulom hit upon a novel way of combining the virtues of tree search with the efficiency of Monte Carlo. He christened the new algorithm Monte Carlo Tree Search, or MCTS, and in January of 2006, his program Crazy Stone won its first tournament. He published his landmark concept in a paper that changed Go programs, setting a dividing point for programs before MCTS and those after.
Remi Coulom (left) and his computer program, Crazy Stone, take on grandmaster Norimoto Yoda
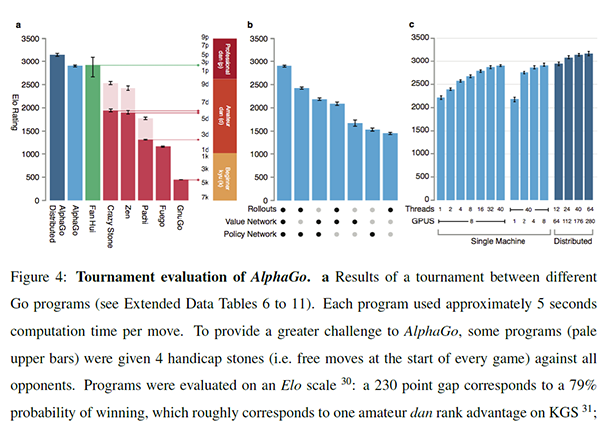
This led to a revolution in Go programs that experienced a massive burst in strength, and now the very best version of Crazy Stone, running on a 64-core PC was able to hold its own against a pro, albeit 65 years old, with only a four-stone handicap in an exhibition game. Again, this is hard to quantify in chess terms, but it would probably be equivalent to a 2200 Elo performance or so. A long way from becoming world champion, but a massive leap forward from the recent heyday of weak amateur software. Until today, Crazy Stone has remained the absolute best Go program, together with rival Zenith Go, based on Coulom’s concept.
A screenshot of Crazy Stone, distributed by Unbalance
Where does AlphaGo come in the story? The problem with the Monte Carlo technique is that there was no obvious way forward. Doubling the CPU power does not lead to a significant increase in playing ability. In chess it equates to one ply, or 50 Elo, but not in Go. After all, gaining a move would require far more than just doubling the computing power, and even then it would be one move ahead in a game that will last over 200 moves. In other words, a drop in the proverbial bucket. Unless some other way to progress was found, a new wall had been reached in Go software progression.
Given this understanding, then even if Google and DeepMind were to somehow get the world’s most powerful supercomputer behind a refined version of Crazy Stone, it might be a bit smarter, and a couple of moves deeper, but nothing a world-class player need concern himself with. It is therefore not strange that Lee Sedol’s prediction of a 4-1 win at worst was even seen as generous…. for the program! Four days later, three wins by the program, and the sheer shock by the programming and Go community is understandable. Somehow DeepMind had conjured up some magic that brought Go software from weak master at best, to world beater! The question is simply: how?
AlphaGo and DeepMind
DeepMind Technologies, the developer of AlphaGo, was founded by British Artificial Intelligence researcher Demis Hassabis in 2010, and specialized in building general-purpose learning algorithms. Hassabis, a former chess prodigy in his own right, rated no.2 in the world in the under-14 category just 35 Elo behind Judit Polgar who was no.1, has always had a particular fascination for games, and not just chess. He won the world games championship a record five times, being also an expert in Shogi, poker and Diplomacy to name a few.
Demis Hassabis, Lee Sedol, and Sergey Brin, co-founder of Google (photo: Google DeepMind)
DeepMind Technologies's stated goal is to "solve intelligence", which they are trying to achieve by combining "the best techniques from machine learning and systems neuroscience to build powerful general-purpose learning algorithms". As opposed to other AIs, such as IBM's Deep Blue or Watson, which were developed for a pre-defined purpose and only function within their scope, DeepMind claims that their system is not pre-programmed: it learns from experience, using only raw pixels as data input. Technically it uses deep learning on a convolutional neural network, with a novel form of Q-learning, a form of model-free reinforcement learning. Their system has been tested on video games, notably early arcade games, such as Space Invaders or Breakout. Without altering the code, the AI begins to understand how to play the game, and after some time plays, for a few games (most notably Breakout), a more efficient game than any human ever could.
Excellent overview of Go and AlphaGo with explanations by project leader David Silver, and DeepMind CEO Demis Hassabis
David Silver, lead project manager explains how AlphaGo came into existence: "AlphaGo is actually around two years old, if we have to give it an age. It was a research project with myself and Aja Huang, and Chris Maddison, an intern from Google Brain. We wanted to ask this question, whether a neural network using deep learning can actually learn to understand the game of Go well enough to play reasonably. And so this was a pilot research project. We tried some experimental things, we tried a whole bunch of ideas, and around a year ago we published a first paper on this result and we discovered that actually the neural network by itself could perform remarkably well. It could actually reach the level of an amateur dan-level player without any lookahead at all. Without even adding any search tree in. When I saw this result, I was really taken aback. I'm an amateur player myself. I'm not a very strong player, but I'm aware as a player of the importance of reading out situations, and I kind of found it mind-blowing that a neural network without any explicit reading of the positions would be able to understand a position well enough to reach amateur dan level. And at that time I felt that this was something with a lot of potential and I sat down and talked with Demis, the CEO of DeepMind, and I said 'I really think someone is going to take these deep learning techniques and actually achieve the highest levels of play. I think it's really going to happen. This is something that's in the cards now', and he said, 'let's make sure it's us.' And he really powered up the project."
The end-result was published on January 27, 2016, in a paper in the journal Nature, revealing not only the existence of AlphaGo, but its incredible results by then. As can be seen above, AlphaGo was evaluated as being roughly 1000 Elo stronger than Crazy Stone. Is it any wonder no one could believe how strong it is?
The ground-breaking paper started with the statement:
"We introduce a new approach to computer Go that uses value networks to evaluate board positions and policy networks to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte-Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte-Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs.”
As of March, a match with the legendary player Lee Sedol was organized with a prizefund of $1 million. By now, DeepMind has effectively won the match with an incredible start of 3-0, though the fourth and fifth games will be played out regardless. It is not a complete whitewash for the machine though as Lee Sedol did strike back in game four to prove the machine was not invincible – yet.
The games are all streamed live on the internet with superb commentary by Chris Garlock and professional 9-dan player Michael Redmond, the only Westerner to ever achieve this rank. DeepMind has said it would donate the winnings to charity such as UNICEF.
After a shock loss, Lee Sedol exits the press conference (photo: Google DeepMind)
Broadcasting to the world
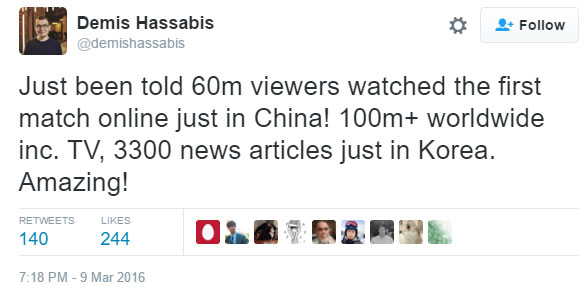
The reception and audience of the match has been incredible, with over 60 million Chinese watching it alone,
100 million people around the world, and no fewer than 3,300 articles in South Korea alone after game one.
Aside from the excellent live commentary provided on DeepMind's official YouTube channel in English, making it possible for even non-players to feel as if they understand what is going on, there are guest appearances by the AlphaGo team before the games start, and 15-minute video summaries of the games being posted after.
15-minute summary of the key Game 3, analyzed by Michael Redmond 9-dan professional and Chris Garlock
At DeepMind's official YouTube channel, there are summaries of the other games, as well as the complete archived
videos of the games.
However, the event's broadcast is hardly limited to this. It is also being streamed and broadcast freely in several languages everywhere in video and on Go servers. There are numerous live video streams, several in English, Chinese, Korean, Russian, you name it. Not only do the organizers not forbid them or restrict coverage, they encourage and applaud them, setting a wonderful example.
Also broadcasting live with Cho Hyeyeon (left), a 9-dan professional, is the official American Go Association,
providing superb commentary. On some days there is Kim Myungwan also a 9-dan pro. Great stuff.
The Japanese also have multiple channels with live commentary by pros
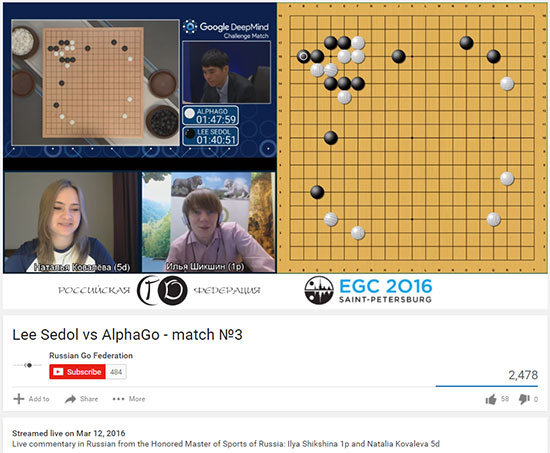
Even the Russian Go Federation brings commentary by strong amateur Natalia Kovaleva,
a 5-dan amateur, and Ilya Shikshin a 1-dan pro.
Needless to say, the major servers such as IGS (Internet Go Server), KGS, and others were
broadcasting to the many fans
In our final report on this historic match, we will bring info on the players, the game, how to play, and more. Stay tuned!
Albert SilverBorn in the US, he grew up in Paris, France, and after college moved to Rio de Janeiro, Brazil. He had a peak rating of 2240 FIDE, and was a key designer of Chess Assistant 6. In 2010 he joined the ChessBase family as an editor and writer at ChessBase News. He is also a passionate photographer with work appearing in numerous publications, and the content creator of the YouTube channel, Chess & Tech as well as the author of Typing Tomes, a powerful typing program.
So, will applying this type of "self-learning" neural net paradigm to a chess playing machine, say, AlphaChess, work? I sense that it will not work because I have seen no mention of this possibility in any of the AlphaGo/DeepMind articles. They mention chess computers, but never ask the basic question of whether this approach works for chess. I tend to think that if you augmented it with the opening and endgame databases, then it might work, but if you left it on its own, it would be in trouble in the opening. Go has opening theory too, but I gather it's not the same as chess. Also, closed games and non-forcing endgames which require long game strategy would seemingly be a real problem for AlphaChess.
In any case, I'd be very interested to hear Demis Hassabis weigh in on this, especially since he was/is a strong chess player.
firestorm 3/15/2016 12:17
thlai, if you don't have a move that improves your position any longer, or would be losing points by playing further (playing inside your own territory/your opponent's territory without your opponent needing to reply to it under Japanese scoring), you pass. If you are playing under Chinese scoring, as a lot of bots do, you can play a move in your own territory or in your opponent's territory without it costing a point.
Can you explain further what you mean? Passing is just the normal way the game ends- there's no "zugzwang"- in the endgame, for example, you end up at the level of 1 point gote moves at the final stages of the endgame- and when they are over, you pass. "Zugzwang" means that you have to move even though every move you can play loses. Yes, you can keep passing, but I wonder what your opponent is doing if they keep moving and you keep passing. As a senior admin on a go site I sometimes have to deal with players who mess other players around by playing stones just to annoy their opponents (they lost and won't accept it), or try to get a win on time- its perfectly reasonable to ignore moves (pass) if they are not a threat to your position. So what is this zugzwang in go that is "slightly different"? Since you can't be compelled to move in a local area (tenuki) or globally (pass), I'd like to know what you mean.
thlai80 3/14/2016 10:25
@firestorm, there's a zugzwang in Go, just slightly different. Yes you can pass, but you can't pass forever. In that case, you either stuck in zugzwang or concede the game.
flachspieler 3/14/2016 10:18
Justjeff wrote on the Coulom-Joda photo:
> Have to love an article that mentions a program testing itself against
> someone 65 years old named Yoda wearing a brown robe.
I also love that situatiion and photo.
But, believe it or not, when it was published there was a very heated
debate in Germany's Go game forum whether it was acceptable that
Coulom showed up at the board in his casual clothes.
Werewolf 3/14/2016 10:09
The program Giraffe is a neural net chess prog, but it only has a neural net for the eval, not the search.
What we need is for someone to continue this work and get a total prog based on NN - then it could be very interesting!
firestorm 3/14/2016 04:58
@ thlai80, go is not good for zugzwang since the concept of zugzwang does not exist in go. In chess you are compelled to move, leading of course to many beautiful studies and problems based on gaining the opposition, giving the opponent the move etc, but in go when you don't have any more productive moves to play, you simply pass. A pass by both sides signify that the game has ended and once the dame (points of no value) have been filled in, the game can be scored for the result. That said, I think being able to play go to a decent level changes and enhances your ability in chess, but that's a complicated matter.
thlai80 3/14/2016 02:32
@MJFitch, learning other board games can actually help to make you more creative in chess. Chinese chess players are very good in queenless chess games and endgames because there's no piece like queen in their version of chess. Reversi/Othello and Go helps in planning and setting traps/zugzwang. Back when I'm all saturated in picking up chess openings, playing a game of Chinese chess could make the brain a little fresher.
X iLeon aka DMG 3/14/2016 12:28
Great stimulating article in a field (neuroscience, neural nets, AI) that I spent some time once upon a moon as a young grad... Ah, memories... Lovely to see the new paths these young guys are taking!
firestorm 3/13/2016 11:33
AlphaGo has lost the fourth game, and after misreading how to reply to a tesuji when in a better position, played a series of really bad moves. This is actually pretty typical for an MCTS-probability based bot, because once their position goes bad all the proper moves give a low value for probability of winning, with the corollary that the unreasonable (to be blunt: downright bad) moves become more attractive because their probability of "success" is higher based on bad replies by the opponent. Basically, there is a breakdown in the quality control of "my opponent will play the best move" and "this move is the most reasonable in the position".
So we saw two things in the fourth game: that the bot can misread a tesuji (tactic), and that when it gets a position which generates low probability of winning, it acts like other p-based (MCTS) bots and can play very, very badly indeed.
This is actually a very difficult problem to solve, since if you tinker with the evaluation algorithm the performance overall degrades- its hard to solve generically, which is why (on a personal note) I still prefer a rule-based approach to programming a go bot. But anyway.
Returning to Lee's match, what was striking for me was the similarities with the Kasparov - Deep Blue match, in which Kasparov was faced with a much stronger opponent and moreover, one he had not been able to prepare for- neither, I would wager, had Lee Sedol. So it wasn't too surprising that against an immensely strong MCTS bot (with a lot more going on, to be fair), that Lee could lose the initial games- as Kasparov said, there is psychological pressure that makes you question your own judgement. Now that Lee has beaten it in the fourth game he knows it can be beaten, and that, like playing a computer in chess (before they got too strong), you had to adopt particular strategies to do so. Amashi (the strategy used by Lee in this game- think poisoned pawn in the Najdorf to get an idea) worked pretty well, but imho, Lee was lost before AlphaGo misread the tesuji at move 78 by Lee.
At least two things are apparent- Lee should get a rematch with time to study the games, and another pro should play it- Park Jungwhan would be my choice, though Ke Jie has good claim to being the strongest player in the world at the moment. Lee Changho would be a really good match also, though I guess you could argue he's not in his prime any more.
Congrats to google for investing and making this happen. And to those who say "go players say go is too hard to solve with programming compared to chess", the go players I know have always said its harder, not too hard. I think that's fair- its not a lack of investment but that different approaches are needed.
tigerprowl2 3/13/2016 10:45
Why is this important? Computers beat any human? Been there, done that, I wear the John Henry sweater.
MJFitch 3/13/2016 07:03
Excellent article!!!...Congrats to team AlphaGo for winning this match. I'm sure Lee Sedol while disappointed in his performance isn't going to just sit back and cry about this defeat. He will as all great players do, analyze, reassess et al and come back swinging. I was never really interested in learning other board games like Go & Shogi etc. This has peaked my interest!!!...Maybe this lost can all be summed up as being out of form???...Form as with chess has cause many disappointing results. Hey???...I reiterate, Excellent Article!!!
thlai80 3/13/2016 06:43
The beginning of ultron?!
Rational 3/13/2016 05:25
I have a bit of schdenfreude that the computers have busted go in the same way they busted chess.. Go players used to boast how the game was more subtle than chess and computers would not master it. I always found the aesthetics of chess more immediately appealing than Go though maybe if One learnt more about it one could appreciate the aesthetics of Go, still life's too short.
soimulPatriei 3/13/2016 05:13
It is a very well researched material. When I was child I knew how to play Go but then I abandoned the game because I could not find partners to play with. Unfortunately Go is not so popular in Europe. I am happy that Lee Sedol did win the game number four. How many people would be capable of this after three defeats in the row?
Congratulations again and looking forward to the next article in the serie.
Justjeff 3/13/2016 05:04
Have to love an article that mentions a program testing itself against someone 65 years old named Yoda wearing a brown robe.
Odomok 3/13/2016 04:42
And what if AlphaGo (AlphaChess) is trained with database of high level chess games, will it be able to beat Komodo, Houdini>
hmchess 3/13/2016 04:18
Lee Sedol just won the 4th game. There are still subtle gaps in AlphaGo, which are quite interesting to explore and discuss. However, it takes a brilliant player to push AlphaGo to its limit to induce it to make a mistake. Lee Sedol played brilliantly, especially with his 78th move, which nobody (probably including AlphaGo) saw coming. Another top player, Gu Li from China, called the move "God's play".
flachspieler 3/13/2016 02:52
Thanks for the interesting article. Two remarks:
(i) Today (March 13) Lee Sedol won game 4. New standing 3-1 for AlphaGo.
(ii) The russion pro player mentioned in the article is "Ilya Shikshin",
not Shikshina.
himalayanbear 3/13/2016 10:55
well done alphago!
okfine90 3/13/2016 08:19
Enjoyed the article. A Very nice article!. The author has nicely explained the basic theme in a nice sequential flow. Even after such revolutionary work by computer scientists, unfortunately still today you will surely find people putting a blunt statement something like " A computer has no intuition and wins due to it's calculating power ???" . This article will encourage such people to explore more about machine learning/neural networks(at least the concepts if not understand the very complex theory). Computer science could easily be the greatest tool currently?. Indeed it's the science of problem solving!.
YOUR PERSONAL CHESS COACH - Whether you’re taking your first steps into the world of club chess, or already playing at a tournament level: with FRITZ, you can train more efficiently, intelligently and with a more personalised approach than ever before.
Videos: Felix Blohberger presents the surprise weapon 4…a6 in the Four Knights Game. Mihail Marin analyses the English Opening with 1.c4 e5 2.g3 g6 3.d4 exd4 4.Qxd4 Nf6 5.Bg2 Nc6. Plus the ‘Lucky bag’ featuring 37 analyses by Berg, Radjabov and others.
Renowned for its solidity and strategic soundness, it has been a cornerstone of the repertoires of elite grandmasters including Fabiano Caruana and Ian Nepomniachtchi, who relied on it successfully in the Candidates Tournament.
The Benko Gambit is back at the very highest level - and it's easy to see why. Black sacrifices a pawn to seize the initiative on the queenside, obtaining long-lasting pressure, active pieces and open files that make life difficult for White.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated Dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
The Hyper-Accelerated dragon is fast, from the very first moves, your bishop heads to g7, seizes the long diagonal, and turns into the most feared piece on the board.
It rewards players who love initiative and clear attacking plans.
“Mate is great!” – Tactical training with Oliver Reeh, “The 8th rank” – Andy Woodward analyses his game against Magnus Carlsen from TePe Sigeman 2026, “A modern Nimzo-Indian” – Andrei Volokitin introduces readers to "his" system and much more!
€21.90
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, analysis cookies and marketing cookies may be used in addition to technically required cookies. Here you can make detailed settings or revoke your consent (if necessary partially) with effect for the future. Further information can be found in our data protection declaration.
Pop-up for detailed settings
We use cookies and comparable technologies to provide certain functions, to improve the user experience and to offer interest-oriented content. Depending on their intended use, cookies may be used in addition to technically required cookies, analysis cookies and marketing cookies. You can decide which cookies to use by selecting the appropriate options below. Please note that your selection may affect the functionality of the service. Further information can be found in our privacy policy.
Technically required cookies
Technically required cookies: so that you can navigate and use the basic functions and store preferences.
Analysis Cookies
To help us determine how visitors interact with our website to improve the user experience.
Marketing-Cookies
To help us offer and evaluate relevant content and interesting and appropriate advertisement.