Replaying history
Chess engines are powerful tools used on a regular basis by chess professionals and amateurs alike in analysing and understanding individual positions and openings. Recently, neural network chess engines such as AlphaZero, Leela Chess Zero, the Stockfish NNUE and Fat Fritz have emerged as powerful chess engines that are able to challenge more traditional engines which use manually implemented evaluation functions.
Chess engines that are entirely self-taught through reinforcement learning, like AlphaZero, don’t use hand-coded evaluation functions. Instead, they learn to select moves and evaluate positions using data created by playing against themselves (known as self-play training). During self-play training, the network transitions from moving entirely at random through to intelligent move selection and insightful position evaluation. This training process allows us to ‘replay history’: we can rerun the training process to see if it turns out differently, and compare it to how human chess knowledge has evolved over centuries.
When the DeepMind and Brain researchers began to compare human history to AlphaZero training, some surprising patterns began to emerge. By using Chessbase’s extensive dataset of human chess games, they were able to build up a history of human move selection and opening theory, and examine this side-by-side with AlphaZero training runs. Andrei Kapishnikov from Google Brain, one of the paper’s lead authors, explains:
“From recorded data, we can see that everyone seemed to play e4 in the 1500s. Over centuries, moves like d4, Nf3 or c4 emerged as credible and fashionable alternatives. When we look at AlphaZero, the picture is flipped. The AlphaZero neural network is initially filled with random as its ‘weights’, and therefore experiments with all possible moves. Only after some rounds of self-play does it figure out that many of those are suboptimal.”
This is indeed what we see in the following figure, which compares human history against AlphaZero’s historical preferences during training:
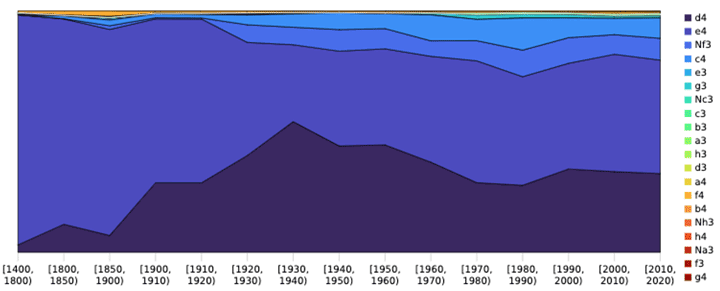
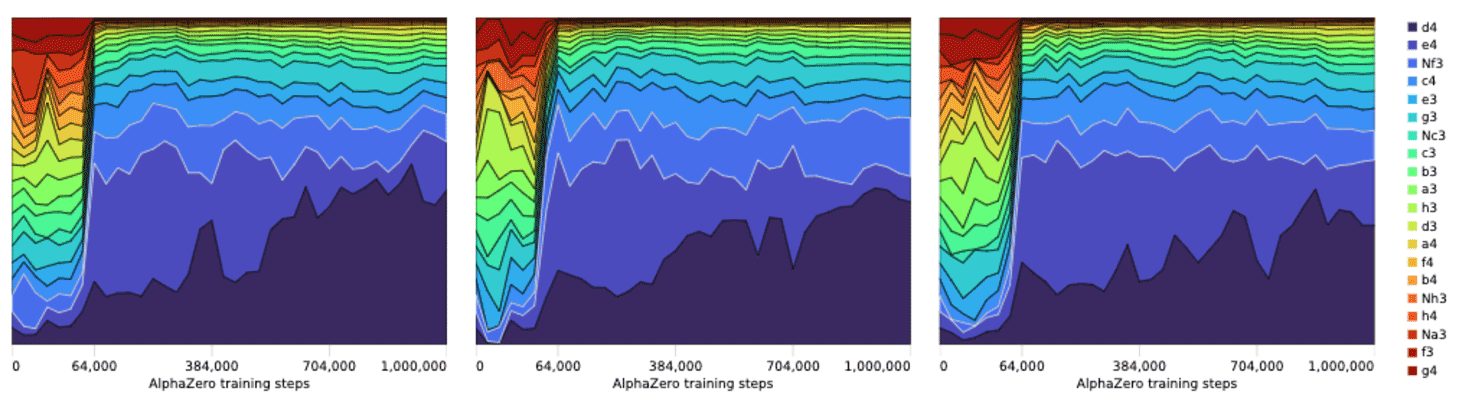
Click to enlarge
If different versions of AlphaZero are trained, the resulting chess players can have different preferences. There are versions of AlphaZero that will play the Berlin defence to the Ruy Lopez, but other versions of AlphaZero will prefer the equally good classical response, a6. It is interesting as it means that there is no “unique” good chess player! The following table shows the preferences of four different AlphaZero neural networks:
| |
AZ version 1 |
AZ version 2 |
AZ version 3 |
AZ version 4 |
| 3… Nf6 |
5.5% |
92.8% |
88.9% |
7.7% |
| 3… a6 |
89.2% |
2.0% |
4.6% |
85.8% |
| 3… Bc5 |
0.7% |
0.8% |
1.3% |
1.3% |
The AlphaZero prior network preferences after 1. e4 e5 2. Nf3 Nc6 3. Bb5, for four different training runs of the system (four different versions of AlphaZero). The prior is given after 1 million training steps. Sometimes AlphaZero converges to become a player that prefers 3… a6, and sometimes AlphaZero converges to become a player that prefers to respond with 3… Nf6.
How does AlphaZero evaluate positions?
AlphaZero’s neural network evaluation function doesn’t have the same level of structure as Stockfish’s evaluation function: the Stockfish function breaks down a position into a range of concepts (for example king safety, mobility, and material) and combines these concepts to reach an overall evaluation of the position. AlphaZero, on the other hand, outputs a value function ranging from -1 (defeat is certain) to +1 (victory is guaranteed) with no explicitly-stated intermediate steps. Although the neural network evaluation function is computing something, it’s not clear what. In order to get some idea of what’s being computed, the DeepMind and Google Brain researchers used the Stockfish concept values to try to predict AlphaZero’s position evaluation function (similarly to the way piece values can be obtained by predicting a game’s outcome).
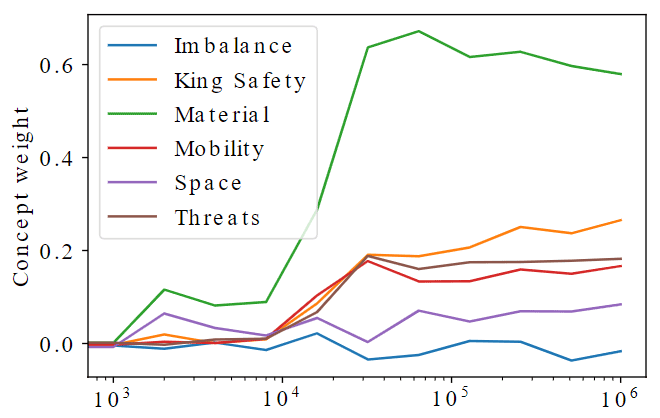
Training steps
This approach allowed the researchers to get estimates of what AlphaZero values in a position, and how this evaluation evolved as self-play training progressed. As the figure above shows, material emerges early as an important factor in AlphaZero’s position evaluation, but decreases in importance later in training as more sophisticated concepts such as king safety rise in importance. This evolution is surprisingly human-like: early in the process of learning chess we evaluate positions simply by counting pieces, before getting a richer understanding of other aspects of a position as we learn more. Interestingly, the rapid jump in understanding of the importance of material around 32,000 training steps matches the point in training at which opening theory begins to evolve, suggesting that this is a critical period for AlphaZero’s understanding of chess.
What is AlphaZero computing?
If we want to understand why a human player chose a particular move, we can just ask them, and get some insight into their thinking process. If we do this with experts - as the famous chess-playing psychologist Adrian de Groot did with world-class players such as Max Euwe and Alexander Alekhine in his thesis ‘Thought and choice in chess’ - we might learn something important. We can’t do that with AlphaZero, but working with neural networks rather than humans has its advantages as well: they never get tired, so we can evaluate hundreds of thousands of games, and we can store all their internal workings in complete detail and study them at length, whereas human brains are hard to study and we can only get very partial recordings. Although we can’t yet ask neural networks to explain themselves in the same way humans can, we can probe their inner workings and try to understand them better.
A good first step towards understanding is to determine if we see chess in a similar way. The DeepMind and Brain researchers made use of a technique called non-negative matrix factorisation to investigate AlphaZero’s internal workings (often referred to as its activations). This technique has been used to separate the network’s activations into a series of factorss, such as done in to understand image recognition networks. This data, which the researchers make available online shows some surprising results: many of these factors, which were learned entirely from self-play training with no human intervention, look surprisingly interpretable - for instance showing threats from the opponent’s pieces, as well as good candidate moves for the player.

Click to enlarge
Tom McGrath, the paper’s other lead author, explains:
“It’s amazing to be able to look inside AlphaZero and see things we can understand! Looking at these factors is an interesting puzzle: sometimes it’s not obvious what they are, but with a bit of thought it can become clear. Of course, there’s still a lot to do - there are loads of factors we don’t understand yet, and we don’t know how they relate to one another. Still, it’s encouraging that we’ve been able to make some progress, and I’d be excited to see if anyone can figure out the meaning of other factors.”
The DeepMind and Google Brain researchers also searched for a wide range of chess concepts within the AlphaZero network’s activations. Surprisingly, many of these concepts could be accurately predicted when the network was well-trained, suggesting that the network’s internal computations may have more in common with human understanding of chess than is widely believed, even though it learned in a different way and often plays differently. The implications of their results are clear: we’ve only just begun to scratch the surface of what AlphaZero has to teach us about chess, and a closer look at the network’s behaviour and internal workings will almost certainly reveal much more.
Full paper

Submitted on Wed, 17 Nov 2021 17:46:19 UTC (6,746 KB):
Acquisition of Chess Knowledge in AlphaZero
Thomas McGrath, Andrei Kapishnikov, Nenad Tomašev, Adam Pearce, Demis Hassabis, Been Kim, Ulrich Paquet, Vladimir Kramnik
Abstract: What is being learned by superhuman neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.
Comments: 69 pages, 44 figures
Subjects: Artificial Intelligence (cs.AI);
Machine Learning (stat.ML)
Download: PDF / Other formats
The URI http://arxiv.org/licenses/nonexclusive-distrib/1.0/ is used to record the fact that the submitter granted the following license to arXiv.org on submission of an article:
- I grant arXiv.org a perpetual, non-exclusive license to distribute this article.
- I certify that I have the right to grant this license.
- I understand that submissions cannot be completely removed once accepted.
- I understand that arXiv.org reserves the right to reclassify or reject any submission.