








I have mentioned the evolutionary change in computer chess. What I refer to is the fact that the last seven or eight years saw some striking changes in computer chess that were not merely “more of the same”. Three extraordinary things happened at the start of that time-span that changed the playing field.
Hardware steadily improved to the point that around 2004-2005 a capabilities threshold was crossed, and it became possible to test and improve chess programs in ways that were not really feasible on old Pentium IIs and IIIs.
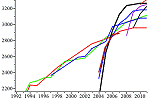
Taken together, these changes amount to nothing less than what Thomas Kuhn calls a paradigm shift. To illustrate my point we only need to study the patterns in program Elo strength over the past two decades. The following two charts are derived from historical SSDF and CCRL data.
The first chart below shows that chess programs in the past were “slow climbers”. Venerable chess programs such as Fritz, HIARCS, Junior, Shredder, etc. progressed steadily and relatively slowly in conjunction with hardware over a long period of time. All top engines from the early 1990s through 2004 fall into this category.
Then something happened in 2004-2005: all new leading chess programs became ultra-fast climbers. Note the slopes of Elo improvement (on the y-axis):

What happened? Starting with the release of the first open-source Fruit in mid-2004, and continuing with the release of subsequent versions of Fruit, open-source engine Stockfish, and especially the release of reverse-engineered Rybka derivatives, highly detailed recipes for building strong, modern chess engines have been in the public domain. Fledgling chess programmers as well as programming veterans have not failed to take notice and the state of the art has advanced rapidly. As a result of this spread of knowledge new programs receive a tremendous performance boost and become “fast climbers”.
Robert Houdart, author of current Elo-leader Houdini, provides a short and refreshingly candid acknowledgement confirming this thesis on his website:
Without many ideas and techniques from the open source chess engines Ippolit [a Rybka 3-based derivative --SR] and Stockfish, Houdini would not nearly be as strong as it is now.
Focusing on the last seven years, a number of chess engines either sharply improved around the time that Fruit source code was released, or debuted after Fruit and then soared:

Rajlich comments on the phenomenon:
In general top engines always improve in lockstep - the strongest engines are always within 50 to 70 Elo of each other, no matter how fast the top guy is improving. I think this is because the general approach to computer chess is essentially established (unlike say poker), so ideas transplant very naturally from engine to engine. So I think that in 2005 the improvement is probably due to Fruit, between 2005 and 2010 or so the improvement is probably due to Rybka, and most recently it's probably due to Houdini.
Now, how do the above points relate to the question of program originality?
Well, first of all, a common-sense observation. The charts show how much stronger Rybka was than some of its top rivals such as Fritz and HIARCS. Rybka was as much as 150 Elo ahead of the pack on equal hardware (Rajlich is being modest in his quote above), an extremely impressive achievement and strong evidence that Rybka was substantially original. It had to be, because from first release Rybka was already far ahead of Fruit, and the gap just kept widening:
 The next point, less obvious but nonetheless true, is that it is much easier to improve the Elo of your own engine if one or more engines exist that are stronger than yours. A programmer can tune their engine to play like the stronger engine, which is what many chess programmers have done by playing their engine against a stronger one, sometimes even going so far as to play millions of games in an effort to reverse-engineer the chess knowledge contained within the stronger engine.
The next point, less obvious but nonetheless true, is that it is much easier to improve the Elo of your own engine if one or more engines exist that are stronger than yours. A programmer can tune their engine to play like the stronger engine, which is what many chess programmers have done by playing their engine against a stronger one, sometimes even going so far as to play millions of games in an effort to reverse-engineer the chess knowledge contained within the stronger engine.
It is much more difficult to improve your engine at the same rate when you are far ahead of the field because you do not have a stronger engine to emulate or measure yourself against. Yet Rajlich managed to consistently do exactly this with Rybka between 2005 and 2010. The amount of original, path-breaking work that must have occurred to achieve this feat is truly staggering.
Next, note that even a “slow climber” like HIARCS had its biggest Elo jump in twelve years just six months after the Fruit 2.1 source code was released (in version HIARCS 10). Multiple WCCC-winning Junior made an even more dramatic improvement after the release of Fruit. For that matter, not a single new (and serious) program that came after the release of Fruit followed the old-paradigm Elo growth curve.
However, these facts do not merely suggest that everyone in the top tier of chess programming learned from Fruit. Retrospectively, what now seems clear is that Fruit also unwittingly triggered a revolution in the whole ethos of chess programming. From the emergence of Fruit and going forward, the premise within the programming community was that it was perfectly fine to re-use and share ideas and algorithms from leading programs whether they were open source or not. This was a new attitude which led us to the current landscape in computer chess.
With hindsight, it seems the ICGA did not recognize the transformation that took place in computer chess following the release of Fruit. For failing to recognize the change and its implications in 2004-2005 the ICGA can certainly be forgiven; institutions almost never immediately see when long-established traditions and norms have quietly slipped into obsolescence. But for them to still not recognize in 2011 how the chess software development panorama had changed, and to fail to adapt accordingly, risked putting the integrity of the WCCC enterprise in jeopardy, and indirectly resulted in the venerable organization being led astray.
While Fruit’s release was the first indication that the game was changing, it was at first not plainly obvious to everyone that Fruit was revolutionary. Initially, the only ones who recognized it for what it was were chess programmers, who over a period of time learned from the program and adapted ideas in bits and pieces to their own designs.
What made Fruit such an epochal breakthrough was not really new ideas in evaluation or search, two of the most critical components of a chess engine. There were improvements in these areas to be sure but they were relatively incidental. The thing Letouzey accomplished, which changed computer chess forever, was to express old ideas far more cleanly and efficiently than anyone else had done before. Fruit had a visionary program structure, and this stride forward in 2004-2005 was made all the more significant by his choice to make the program open source.
What happened next is a tale many in the hobby know well. Rybka was released six months later incorporating every useful Fruit idea that could be incorporated, and adding many more improvements. As I have established, Rybka assumed a position of huge dominance. Other program authors likewise learned from Fruit and went after Rajlich like a pack of hounds chasing a fox.
But then something unprecedented in computer chess happened. In May 2007 a strong closed source program called Strelka (literally "arrow" in Russian, but a reference to a Soviet canine that orbited the Earth) was released by a hitherto unknown individual going by the name 'Jury Osipov'.
This program was immediately thought to be a very close derivative of Rybka because its solving of test positions was extremely similar. But, beyond the objective measures of similarity testing, Strelka had to have been a reverse-engineered Rybka derivative because, at the time, a new program of such strength and manifest similarity in its playing style could hardly have come from anywhere else. Thus a very public precedent was established: someone had reverse-engineered a closed-source program with impunity.
The next step on this path came in January 2008 when Strelka 2.0 was released, this time with open source code. In other words, Rybka 1.0 Beta’s secrets were now revealed for any programmer to use. Is any reader gullible enough to think the community of chess programmers took the moral high ground at this point, condemned ‘Osipov’, or refused to even take a look at Strelka's source code?
Sometime thereafter someone with larcenous intent approached Rajlich via email posing as GM Larry Kaufman. The result of that caper was that another key Rybka secret, namely how Rajlich tuned his evaluation, was inadvertently revealed to dishonest individuals whose apparent goal was to forcibly strip every last bit of proprietary information from Rajlich.
Fast forward to mid-2009. Rybka 3 was reverse-engineered by a group of chess programmers using fake names (Yakov Petrovich Golyadkin, Igor Igorovich Igoronov and Roberto Pescatore, i.e. an Italian rendition of Bobby Fischer). This effort was published on the Internet as the IPPOLIT program, and soon thereafter chess programmers were freely using this source code to create strong Rybka-flavored derivatives, such as Robbolito and IvanHoe.
In a Talkchess forum post sent to Sven Schüle, a German chess program author, Rajlich wrote:
Ippolit is disassembled Rybka 3 with changes. The changes are considerable but not even close to enough to leave any doubt. Robbolito is an evolved Ippolit, with more changes and more cleanup. I haven't checked the other new engines yet.
Initially, some competing programmers expressed qualms about using code produced by fake-named authors. But apparently the temptation became too great and the ideas were taken.
I recite this well-known history to provide the reader with background context. What is clear is that Rajlich's original ideas have been lifted from various reverse-engineered editions of Rybka again and again and again--his work has been pilfered as comprehensively as anyone's in all of computer chess history. A number of leading programs have rather obviously benefited: in practical improvements to their programs, in tremendously reducing their development time, and in gaining insights they might never have developed on their own. Yet, it is Rajlich who was investigated and found guilty of plagiarism in absentia, banned for life, stripped of titles, and vilified in the international press over a five-year-old tournament rule violation.
Ironically, it is the ICGA which may have committed an illegal act in publishing a disassembly of Rybka 2.3.2a, a commercial product still under license, on the Internet:
Article 6 of the 1991 EU Computer Programs Directive allows reverse engineering for the purposes of interoperability, but prohibits it for the purposes of creating a competing product, and also prohibits the public release of information obtained through reverse engineering of software.
The first thing that must be addressed regarding the ICGA’s finding that WCCC Rule 2 was violated is the formal language they use in their allegation. They specifically accuse Rajlich of “plagiarism”. I note that the writers of this charge are scholars with doctoral degrees and are men whose profession obliges them to choose their public words with careful precision.
Consequently an important distinction must be made that is more than merely semantics: Rajlich provably did not commit the dictionary definition of plagiarism:
The unauthorized use or close imitation of the language and thoughts of another author and the representation of them as one's own original work, as by not crediting the author.
From the initial release of Rybka 1.0 Beta until early 2011 the general consensus in the computer chess community was that Rybka was an original program, even though it had undoubtedly learned a great deal from the leading open source programs in existence in 2005, Fruit and Crafty. This consensus was based on Rybka’s position on the Elo rating lists and steadily increasing strength, its search behavior, unique features, etc.
Rajlich conceded from the very beginning that he had studied Fruit’s open source code very closely and learned a great deal from it. In an interview from 2005, right after Rybka 1.0 Beta was released, Rajlich acknowledged the computer chess community’s as well as his own debt to Fruit:
Yes, the publication of Fruit 2.1 was huge. Look at how many engines took a massive jump in its wake: Rybka, HIARCS, Fritz, Zappa, Spike, List, and so on. I went through the Fruit 2.1 source code forwards and backwards and took many things.
Rajlich later publicly praised the work of Fabien Letouzey:
I don't want to get too specific about which ideas from Fruit I think are really useful, but they fall into two categories:
1) Very specific tricks, mostly related to search.
2) Philosophy of the engine (and in particular of the search).
Fruit could really hardly be more useful along both of these dimensions. Fabien is a very good engineer, and also has a very clear and simple conception of how his search should behave.
Finally, Rybka 1.0 Beta’s Readme file gave credit to Fruit in a “Special Thanks” section:
…for Fruit, which shattered a number of computer chess myths, demonstrated several interesting ideas, and made even the densest of us aware of fail-low pruning.
By definition, plagiarism only happens when credit to sources is not given, which was never the case with Rybka. These acknowledgements were widely known at the time Rybka entered WCCC tournaments and, rather obviously, Rybka’s debt to Fruit steadily diminished over the years as program improvements superseded the original program code in Rybka 1.0 Beta.
If these acknowledgements were insufficient to satisfy WCCC Rule 2, then we must return again to arguments made earlier on the inadequacies of the rule itself and how it is applied.
If plagiarism did not actually take place, then what is the actual nature of the ICGA’s complaint? Answer: the ICGA has no complaint at all unless it directly and without equivocation asserts that Rajlich copied original source code and used the resultant chess program in a WCCC tournament competition.
Whether or not he speaks for the ICGA, code-copying is precisely what leading ICGA panelist and secretariat member Dr. Robert Hyatt has made dozens (if not hundreds) of times in the Rybka forum. While Hyatt is not officially an ICGA spokesman (only Dr. David Levy can speak for that organization), he did lead the Rybka investigation, he wrote or supervised the ICGA report, he energetically and persuasively presented his arguments to other panel members, and in the time since he has made several thousand online posts in defense of what was done. A discussion of the ICGA report can scarcely be conducted without extensive reference to his views on the case against Rajlich. Accordingly I will develop the Rajlich defense under the assumption that Hyatt speaks for the ICGA.
I will start my rebuttal to the ICGA’s technical findings by addressing a subject that is not addressed in the ICGA report, but ought to have been.
When comparing two chess engines recreationally what really matters to us as hobbyists and what makes it all so engrossing is how differently they play. On the other hand, when comparing chess engines in a code-copying investigation what really matters is how similarly they play. After all, the sole function of a chess program is to play chess. Would you think it acceptable if two chess programs played exactly the same moves while having completely different program code? Obviously not, as this would be prima facie evidence of a direct translation of program A into program B, rather than an original program.
To put matters into better perspective let’s consider the chess evaluation similarities between Fruit 2.1 and Rybka 1.0 Beta compared to the similarities between other chess engines.
In an interview with Nelson Hernandez Rajlich suggested that one measure of originality and similarity of chess engines can be quantified by considering ponder-hit rates “(the percentage of the time two programs will come up with identical moves in a large number of selected positions). Kai Laskos, a computer chess theorist with statistical expertise who posts in the Talkchess computer chess forum, took up the challenge and performed a statistical analysis of ponder-hits using a similarity-testing program written by chess programmer Don Dailey. This analysis produced statistical "fingerprints" of a number of chess engines. Then, employing a hierarchical clustering algorithm, he produced a number of dendrograms (using IBM SPSS) that elicited some surprises but also confirmed what was already known. Bear in mind Rajlich had no idea a rigorous analysis would actually be performed when he was interviewed by Hernandez; the results could easily have proven him a liar.

Dendrogram comparing ponder-hit similarity of numerous chess engines. Thanks to Kai Laskos for creating this chart and posting it to the Talkchess forum
The way to read the chart is as follows:
Laskos points out that Junior 12.5 (not shown) appears unrelated to anything, and that relationships at a large distance from the left edge (~20) are most likely statistical noise.
Note that Strelka 2.0 is an admitted clone of Rybka 1.0 Beta; you can see that by how very close to the left they diverge.
Three distinct clusters of derivative engines can be identified:
Programs that are Fruit derivatives (children of the yellow circle): note that Rybka 1.0 Beta is not one of these
Programs that are Stelka 2.0 derivatives, which is a Rybka 1.0 Beta deriivative that was obtained through reverse engineering (children of the green circle)
The Strelka/Ippolit/Robbolito/Ivanhoe/Houdini program cluster (children of the brown circle, not all of which appear in the dendogram), which trace their origins to a reverse-engineered version of Rybka 3
The ponder-hit “fingerprints” show that the similarity between Fruit and Rybka 1.0 is actually not that large, and certainly not when compared to other programs. Moreover, the difference between Fruit and later versions of Rybka 3 and Rybka 4.1 is so large (~20) that it’s fair to say there is no similarity at all in practical terms.
Given the data-set used by Laskos the probability of “over-fitting” in his chart seems low, and thus his results appear statistically significant. The similarity fingerprints suggest that Rybka 1.0 Beta was actually remarkably “clean”, and much more so than numerous engines that have emerged in the years since. Note the irony: the chess program that has been the most influential to the others over the past several years (for very good reasons) is the target of plagiarism allegations!
Dr. Miguel Ballicora, author of chess program Gaviota, came up with similar findings based a larger set of data. A large set of program “trees” is vitally important to identify program similarity, because with more data ‘families’ of programs emerge more clearly. Ballicora found that the relationship between Fruit and Rybka is NOT significant. With more data you soon realize that the distance between Rybka 1.0 Beta and Fruit 2.1 is not less than other unrelated engines.
In no way do I mean to suggest that the approach taken by Dailey and Ballicora is necessarily the best or only way to objectively measure program similarity. Ponder-hit analysis is not perfect and it may be possible to fool the methods that have been advanced. But ponder-hit analysis does provide one measure of value that, combined with other techniques, could result in a robust suite of originality tests. It is a promising methodology simply because it is based on hard numerical data and methods that can be applied to all programs in the same way. Additionally, it has the benefit of being conceptually easy to understand. In time, improvements to this approach will undoubtedly emerge and, hopefully, settle the most visible and relevant basis for comparison: how a chess program actually plays.
The widely understood ‘originality’ standard among programmers is that they may adopt the ideas of others but not duplicate their actual source code. The problem that has emerged with this construct, and intensified in recent years, is that many of today’s programs have been influenced by the work of other programmers, and sometimes heavily. Theoretically this could have happened in such a way that one program that has directly or semantically copied portions of source code could easily be more dissimilar to its unacknowledged source in actual play than another program, which copied nothing, but rigorously applied and then obfuscated ideas and algorithms taken from the same source.
An aspect of the originality problem was summarized by Fabien Letouzey in a 2008 interview:
I am sorry to say that whether an engine is someone's "own work" makes little sense to me, although I understand that tournament directors would like a clear yes or no.
The reason is that all engines, whether amateur or commercial, share most of the techniques. Alpha-beta (of which PVS, NegaScout and MTD(f) are only derivatives), iterative deepening, check extensions, null move, etc ... are shared by most and have been published, mostly by researchers, some of them more than 30 years ago! Sure there are many different ways to represent the board and pieces but it only affects speed, which rarely amounts to more than a few dozen Elo Points.
The ICGA’s core finding of code similarity relates to Rybka’s evaluation function, which it is asserted came from Fruit. But from where did Fruit's own evaluation function originate? Letouzey explains in the same interview that Fruit’s positional evaluation function is itself not, strictly speaking, original:
I can't think of a search feature in it that was not described before. Ditto for evaluation terms (except perhaps a few drawish-endgame rules that activate in one game in a hundred).
He continues:
Unfortunately my interest in working on evaluation is very low because I don't learn anything in the process and I cannot apply the same changes to games other than chess. For this reason I cannot promise important future development on Fruit.
The ICGA alleges there is a great similarity between Fruit and Rybka 1.0 Beta evaluations but, as I will show next, all their analysis actually demonstrates is that Fruit and Rybka use similar algorithms for their evaluation. Algorithms, let us be clear, are expressions of ideas, not source code. And even if they were source code it is unclear whether such things as evaluation terms (i.e. positional features that are rewarded or penalized in the evaluation, such as doubled or passed pawns, mobility, king safety, etc.) actually count as “game-playing code” as WCCC Rule 2 is currently written.
Thanks to Ed Schröder for encouraging me to write this article as well as his insights on the computer chess scene going back decades. A special thanks to Nelson Hernandez, Nick Carlin, Chris Whittington, Sven Schüle and Alan Sassler for their first class editing as well as their many valuable suggestions. Without the lively collaboration of these individuals spanning several weeks this paper could not have been written. Finally, let me thank Vasik Rajlich for his clarification of various technical points and contemporaneous notes.
Thanks also to Dann Corbit, Miguel Ballicora, Rasmus Lerchedahl Petersen, Cock de Gorter, Jiri Dufek for their excellent suggestions and eagle-eyed proof reading.

Søren Riis is a Computer Scientist at Queen Mary University of London. He has a
PhD in Maths from University of Oxford. He used to play competitive chess (Elo 2300).
 |
A Gross Miscarriage of Justice in Computer Chess (part one) 02.01.2012 – "Biggest Sporting Scandal since Ben Johnson" and "Czech Mate, Mr. Cheat" – these were headlines in newspapers around the world six months ago. The International Computer Games Association had disqualified star programmer Vasik Rajlich for plagiarism, retroactively stripped him of all titles, and banned him for life. Søren Riis, a computer scientist from London, has investigated the scandal. |












