Neural networks in chess programming
For a long time, rule-based approaches were used in chess programming. These programmes used a variety of hard-coded rules and heuristics to evaluate chess positions and select the best moves.
The turning point came with the success of AlphaZero, a chess programme developed by DeepMind (a subsidiary of Google). AlphaZero started with only the hard-coded rules of how the pieces can be moved on the board and when a game is over, e.g. by stalemate or mate. AlphaZero learnt everything else through self-play. The knowledge acquired during this training was stored in so-called neural networks. These networks were later used in the match against Stockfish to evaluate positions. Put simply, the neural networks are responsible for selecting the best move in a position.
The result of the AlphaZero vs Stockfish match clearly showed the advantage of neural networks over hard-coded rules. In the meantime, all engine developers (including the Stockfish community) have followed suit and integrated neural networks into their engines. Probably every reader has already played against an engine that uses such a network. Apart from the improved playing strength of the engine, you don't usually notice it.
But what exactly are neural networks? How do they work, how do you train them, and how do you use them in chess engines? I have looked into these questions and will try to answer them in this article. To do this, I will first explain the basic principles using a "minimal" neural network. In the second part, I will then show how the corresponding principles can be applied to chess programming. As an example, I have chosen the endgame king and rook against king. It sounds simple at first. But the challenges lie in the details. If you don't believe it, you can try programming the corresponding rules (without using tablebases).
Preliminary remarks
When you write an article about a topic as complex as neural networks, there is a risk that it will quickly become very technical and you will get lost in the details. I have therefore chosen the following approach.
In the article, I will describe my approach in such a way that it is (hopefully) possible to follow without in-depth technical knowledge. The technical terms used are explained in the glossary at the end of the article.
For those who are interested in the technical aspects of programming, I will provide links to the programme code. This will be in the form of Colab Notebooks. These notebooks can be thought of as virtual computers that you can operate in your favourite browser. If you follow the links provided, you can execute the code yourself via "Runtime -> Select all". If you are interested, you can change parameters and see what happens. You don't need to have any inhibitions. Nothing can break and it's free.
A simple neural network
Let's first take a look at how neural networks are structured. Such a network initially consists of nodes, which are referred to as neurons. As a rule, these neurons are organised into levels. Each network has at least one input and one output level. There are usually any number of hidden levels between input and output.
 Attacker, coward, swindler or endgame wizard: I'll show you how to win against anyone! After my World Championship victories in 2022 and 2023, I am the reigning Chess Software World Champion and am now looking forward to showing you how to become even stronger against your opponent. With my innovative training method, I simulate typical player personalities you know from tournaments and online chess: brash attackers, cautious cowards, passive players. But how do you win against them? Fritz will show you how!
Attacker, coward, swindler or endgame wizard: I'll show you how to win against anyone! After my World Championship victories in 2022 and 2023, I am the reigning Chess Software World Champion and am now looking forward to showing you how to become even stronger against your opponent. With my innovative training method, I simulate typical player personalities you know from tournaments and online chess: brash attackers, cautious cowards, passive players. But how do you win against them? Fritz will show you how!Neurons on one level are connected to neurons on the next level. There are various approaches to how these connections are organised. However, we assume here that each neuron of one level is connected to all neurons of the next level.
The connections are assigned weights that influence how strongly a neuron influences the corresponding neuron of the next level. In our minimal network, weights are factors by which the value of the source node is multiplied before the value is transferred to the target node. All input values are then accumulated in the target node.
A simple example of such a neural network would consist of an input layer with two neurons and an output layer with one neuron. Hidden layers are not used in this example.
The field of application for this network could be, for example, an experiment from physics lessons where we set two input variables (X1 and X2) ourselves and then measure an output value (Y). The data might look like this:
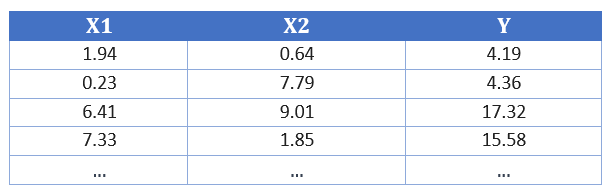
Figure 1: Measured values
The task would now be to predict what value Y has if, for example, we set X1=10 and X2=20. What should a neural network look like with which we can make the prediction? To do this, we create a new Colab Notebook, which can be accessed via this link.
The beginning is simple. We have the two input neurons X1 and X2 and the output neuron Y. We don't need hidden intermediate levels, so we connect both X1 and X2 to Y.
The network would currently look like this:
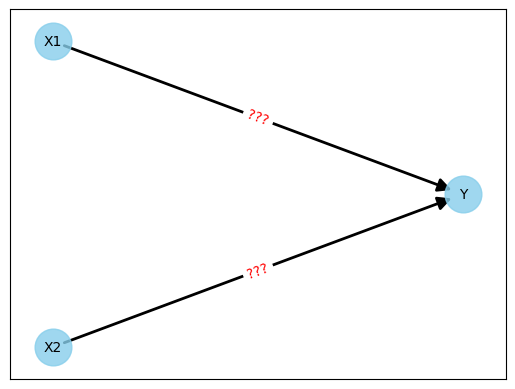
Figure 2: Initial neural network without weights
Now comes the difficult part. What do we do with the weights (shown as "???" in the figure)? How must these weights be chosen so that we can predict Y values as accurately as possible?
With neural networks, this is solved with training. The measured values from Figure 1 are used to train the network.
Training starts with initial weights. There are different strategies for this. For example, you can set all weights to zero or use random values. I decided in favour of random values and then obtained the following network:
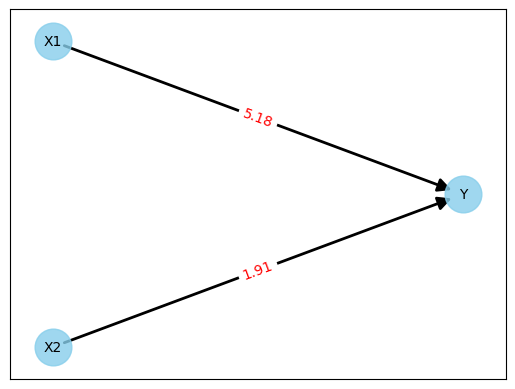
Figure 3: Neural network with random weights
Let's do a quick test with the first line of the measured values from Figure 1.
Y = 5.18 * 1.94 + 1.91 * 0.64
Y = 11.06
That's not good, as we would have expected a result of 4.19; so we are almost off by a factor of 3. But it could have been much worse, as we had rolled the weights. And in fact, it doesn't matter how good or bad the net is at the beginning. The decisive factor is the training (or learning) of the net.
Now let's take a closer look at the training. The following programme sequence, which I have greatly simplified, has established itself as the standard in recent years:
| For all measured values available |
(1) |
| outputs = neural_netz(X1, X2) |
(2) |
| loss = outputs-Y |
(3) |
| do_backpropagation () |
(4) |
| update_weights() |
(5) |
Figure 4: Training a neural network
A brief explanation of these lines of code:
- The following commands are executed for all measured values from Figure 1 (I had provided a total of 100 value pairs).
- This command is used to calculate the output values. The input is the X values (i.e. X1 and X2) and the current weights of the network are used.
- Calculates the loss, i.e. the difference between the calculated values (outputs) and the expected values (y).
- Performs a so-called backpropagation. Mathematical methods are used to determine which weights are responsible for the "loss" in line 3. Based on this, it is then calculated how the weights should be adjusted.
- Carries out the adjustments to the weights in the mesh calculated in step 4.
The main work is certainly done in step 4, but the good thing is that even as a programmer you don't have to think much about this, as there are appropriate frameworks such as PyTorch, which I use, that take over this task.
 The perfect combination: the professional database program ChessBase 17 plus the brand new world champion program Fritz19. This Christmas bundle includes ChessBase 17 as a single program and the full version of the new chess program Fritz19.
The perfect combination: the professional database program ChessBase 17 plus the brand new world champion program Fritz19. This Christmas bundle includes ChessBase 17 as a single program and the full version of the new chess program Fritz19.If you repeat the whole thing a hundred times (it only takes a few seconds), you get the following network:
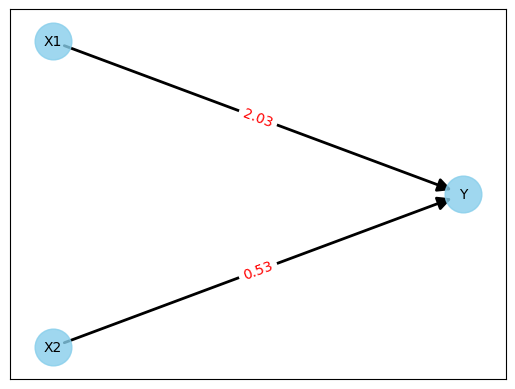
Figure 5: Neural network after training
Let's do the test again with the first line of the measured values from Figure 1.
Y = 2.03 * 1.94 + 0.53 * 0.64
Y = 4.2774
This is not perfect, as the expected result is 4.19. But a deviation of 0.08 (approx. 2%) is close enough for our little experiment.
Note: I had generated the measured values from Figure 1 with random values for X1 and X2 and the formula Y = 2.0 * X1 + 0.5 * X2. The perfect result would have been weights with the values 2.0 and 0.5. If someone uses the Colab Notebook to retrace the steps, don't be surprised if other values come out. This can happen with random numbers.
A neural network for chess
Let us now set about the task of creating a neural network for a chess engine. The task of the network should be to evaluate a chess position as well as possible.
The path from a minimal neural network to a network that can evaluate the entire range of chess positions would be far too long and too complex. I have therefore chosen a simple example for this article, the mating sequence of king and rook against king. Sounds simple, but let's take a look at the following position:
Figure 6: Position king and rook against king (mate in 32 half-moves)
In the starting position, it takes 16 moves (or 32 half-moves) to mate with best play. If you were to set this search depth in an engine with a classic search algorithm (e.g. MiniMax), you would have to wait a very, very long time for the first move, even with good hardware.
If you set the search depth lower, you have to implement a good position evaluation. After all, if you only counted the material, nothing would change, as White would keep his extra rook even with random moves. Of course, there are established solutions for this, such as bonus points in the evaluation if the black king is close to the edge of the board, or the white rook cuts off the king's path, etc. But this is not trivial.
I wanted to take a different approach with the neural network. Instead of explicitly defining rules, I wanted to train a simple engine with a search depth of a maximum of 3 half-moves and without functions for position evaluation in such a way that it wins the above position even if Black plays perfectly.
The steps are analogous to the first example, i.e.
- Define network
- Train network
- Final test
The intermediate step "Provide training data" is still required for training.
Definition of the neural network
Let's first look at how the position in Figure 6 can be transferred into numerical values. There are many ways to do this, but I have opted for the following approach, which is based on BitBoards. There is a separate 8x8 field for each type of piece. If the value is 1, this means that there is a corresponding piece on the square.
The position in Figure 5 would then be represented as follows:
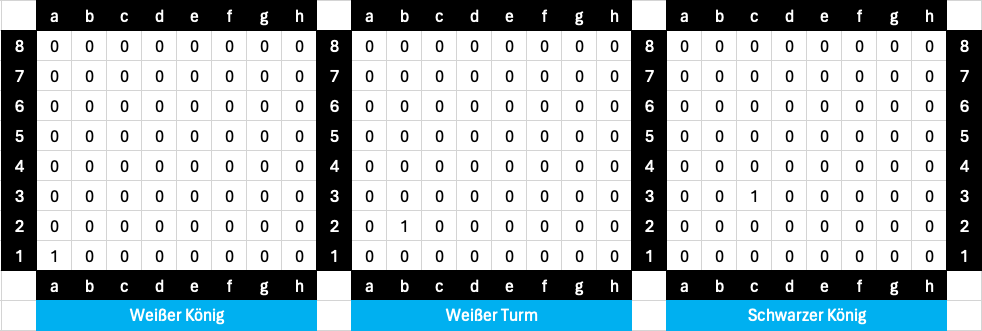
Figure 7: BitBoards for the position in Figure 5
In total, you then have 3x64 bit values, i.e. 192 in total. Another bit is added to indicate whose turn it is (1 = white's turn, 0 = black's turn). This gives a total of 193 bit values.
At first glance, the 193 input values for the neural network look very wasteful, especially as only a small sub-problem of the chess game is to be solved. However, if you take a look at the current Stockfish network structure, you will see that this network, called HalfKA, has 91,000 input values. There are certainly good reasons for this, and the success of the engine proves the developers right. But for our example, that would certainly be overkill.
The output is much simpler. A numerical value is expected that indicates how many half-moves away from mate we are, i.e. a value between 1 and 32 (longest path to mate).
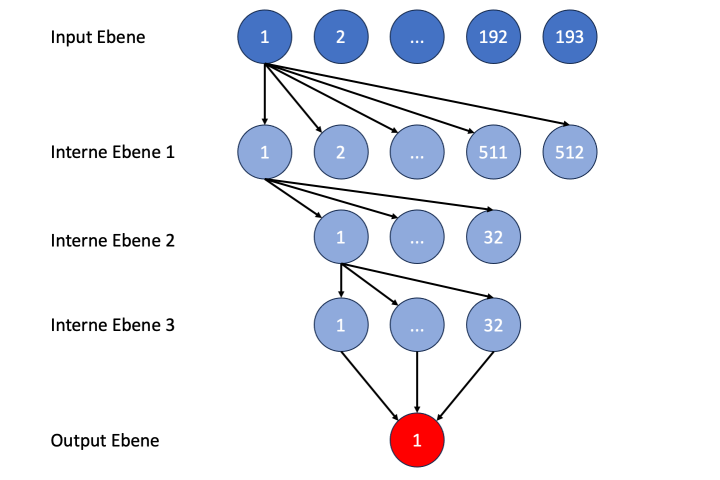
Intermediate levels of nodes are now required in this network. Stockfish used 3 intermediate levels with 512, 32 and 32 nodes in the old network structure called HalfKP. It can't be wrong to adopt this. Our network then looks like this:
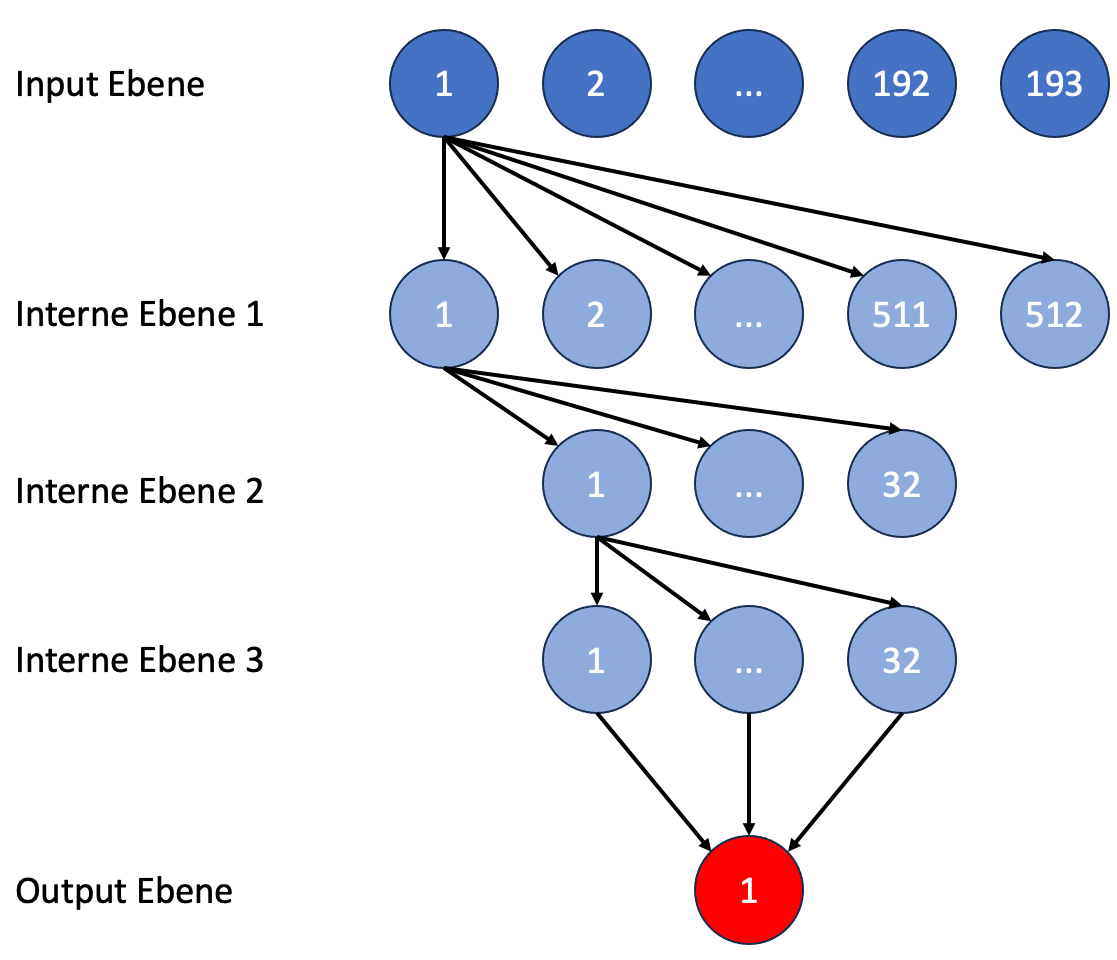
Figure 8: Structure of the neural network for position evaluations (numbers indicate the position of the node in the respective level)
Providing training data
I have created a new Colab Notebook for this task, which can be accessed via this link. In this notebook, I first downloaded a tablebase from the Internet and then used a small programme to create random positions with a white king, a white rook and a black king. I then used the tablebase to calculate the distance to mate for each of these positions. The result was a file with the following lines:
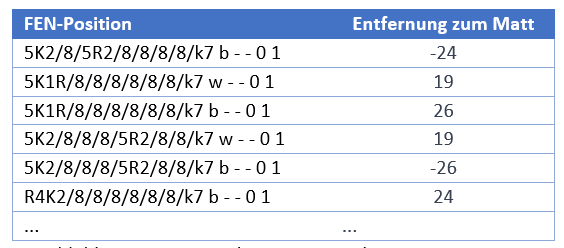
Figure 9: Training data for king and rook against king
Training the neural network
I have also created a separate Colab Notebook for this, which can be accessed via this link. The training works according to the scheme outlined in Figure 4.
 The new ChessBase Opening Encyclopaedia 2024 - More content. More ideas.
The new ChessBase Opening Encyclopaedia 2024 - More content. More ideas.I carried out a total of 50 training cycles (called epochs in technical jargon) with the generated training data. In the referenced Colab, the entire training run takes less than 5 minutes. The following figure shows the progress of the training.
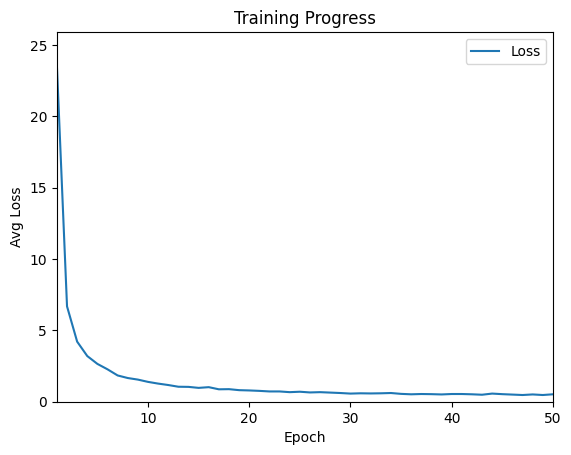
Figure 10: Training progress
You can see that progress is rapid at the beginning. The loss, i.e. the value by which the evaluation of the neural network deviates from the correct value, decreases very quickly. From epoch 20, the value is below 1, after which the progress becomes noticeably smaller. Occasionally, the values even get slightly worse, but then improve again.
The network trained in this way is saved in a file (krk_model.pth) at the end and can then be subjected to the final test.
Final test
Now the moment of truth is approaching. Is the trained net really capable of correctly evaluating positions with king and rook against king?
There is only one way to find out. In the position shown in Figure 6, I let the neural network (KRk model) compete against an engine that always selects the best move using tablebases. The neural network was integrated into the evaluation function of an engine with a MiniMax algorithm that uses a search depth of 3 half-moves. The programme code looks like this:
| def eval (self) |
(1) |
| fen = self.new_board.fen() |
(2) |
| x = get_krk_bitvector(fen) |
(3) |
| eval = self.machine(x) |
(4) |
| return eval |
(5) |
Figure 11: Position evaluation with trained neural network
In lines (2) and (3), the current board position is first converted into the bit structure known from Figure 7. In line (4), the neural network is then called with the bit structure as an input parameter. The output is then the distance to the mate, and this value is then returned in line (5). The corresponding Colab Notebook can be called up via this link.
The engine used is very simple. It checks all legal moves in a position and then evaluates them using the evaluation function in Figure 11. The move with the best evaluation is then selected.
Let us now play this engine against a tablebase engine:
The neural network weakened on the 11th and 12th moves. Only the knowledge that a three-fold repetition of moves was imminent made the engine play Kd6 on move 13. Otherwise, the rook would have continued to oscillate between e6 and e5. This is also the main reason why the neural network needed 4 additional moves instead of the optimal 16.
But the result is impressive. Without having to programme any explicit rules, the neural network quickly gave mate.
I then did the self-test and played this position myself against the tablebase engine. It took me 19 moves to checkmate.
Closing remarks
The self-imposed task of creating and training a neural network that makes it possible to win positions with king and rook against king was fulfilled. The engine used for this only knows the rules of chess (which moves are allowed, what is a mate, what is a threefold repetition of a position, etc.). The neural network takes care of everything else.
The work was not quite as simple and straightforward as described in this article. I had to experiment when defining and training the network, and there were the odd setbacks. But when I got stuck, ChatGPT was there to help and advise.
Next, I would like to train a neural network for the entire spectrum of positions. There is no shortage of training data. Lichess, for example, makes more than 90 million games available for download every month. Approximately 10% of these games have been analysed by Stockfish and therefore contain an evaluation for every move in the game. The whole thing would be a much more complex and time-consuming endeavour than the network described here in the article for positions with king and rook against king. I would therefore be delighted to hear from fellow campaigners. If you are interested, simply contact me via my homepage.
Glossary
 It is the program of choice for anyone who loves the game and wants to know more about it. Start your personal success story with ChessBase and enjoy the game even more.
It is the program of choice for anyone who loves the game and wants to know more about it. Start your personal success story with ChessBase and enjoy the game even more.
|
Concept |
Definition |
|
AlphaZero |
AlphaZero is a computer programme developed by DeepMind (a subsidiary of Google). It is known for its success in board games such as chess, shogi and Go. The special thing about AlphaZero was that only the rules of the game were implemented. It taught itself everything else by means of machine learning. |
|
Bit Board |
A Bit Board is a data structure in chess programming that is used to efficiently represent chess positions. Instead of storing a chess position as a single 8x8 array, Bit Board uses a separate 8x8 array for each type of piece (white king, black king, white queen, ..., black pawn). In the 8x8 array for the white king, the value 1 is for the square on which the king stands and 0 for all other squares. The 8x8 arrays for pawns can have up to eight values. |
|
Colab |
Colab, short for Colaboratory, is a free cloud service from Google that provides a Python programming environment with libraries for machine learning. Colab is widely used in the AI community, especially by those who do not have access to their own powerful hardware. |
|
FEN |
The Forsyth-Edwards Notation (FEN) is a standard notation for chess positions. It makes it possible to describe a position in a line of text, the so-called FEN string.
The Chessbase software provides functions to generate a FEN string for a position or, conversely, to create a position from a FEN string. |
|
MiniMax |
MiniMax is an algorithm used in game theory and artificial intelligence (AI) to determine the best move in a two-player game where each player tries to achieve the best result for themselves (max) and the worst for their opponent (min). |
|
Neural network |
A neural network is a model inspired by the functioning of the human brain. It consists of connected nodes (neurons) organised in layers. It is used to learn complex patterns and dependencies in data and is applied in various tasks such as pattern recognition, classification, regression and more. |
|
Python |
Python is a programming language known for its readability and simplicity of code. It was developed by Guido van Rossum and first published in 1991. Since then, Python has become one of the world's most popular programming languages. Python is used in many areas such as web applications, artificial intelligence, machine learning and automation. |
|
Python Chess |
Python Chess is a popular Python library that provides functions for saving chess positions and generating legal moves in a position. It also supports standard formats such as FEN (Forsyth-Edwards Notation). |
|
PyTorch |
PyTorch is an open-source deep learning library developed by Facebook AI Research. It provides a flexible platform for creating and training neural networks and other machine learning projects.
If you want to learn more about PyTorch, I can recommend this course from Stanford University. |
|
Stockfish |
Stockfish is one of the most powerful open-source chess engines. The engine is used by chess players and developers for analysing and as a benchmark for other chess engines. |
|
Stockfish NNUE |
Stockfish Efficiently Updated Neural Network Evaluation (NNUE) is an improvement of the Stockfish chess engine, which is based on the use of neural networks for the evaluation of chess positions.
A description of both the old HalfKP and the new HalfKA network structures can be found here. |
|
Tablebase |
Tablebases, also known as endgame databases, are databases in which all possible positions in a chess endgame with a small number of remaining pieces are stored. Each position is assigned an evaluation in the form of the distance to mate (if a win is possible with the best counterplay). |