Using Heuristic-Search Based Engines for Estimating Human Skill at Chess
By Matej Guid and Ivan Bratko
University of Ljubljana, Faculty of Computer and Information Science, Artificial
Intelligence Laboratory, Ljubljana, Slovenia. This article is based on a paper
by the same authors published in the ICGA Journal; full reference is given
below.
In 2006, we carried out a computer comparison of world
chess champions. We analysed moves played in World Championship matches with
the chess program CRAFTY, in an attempt to assess objectively
one aspect of the playing strength of chess players of different eras. The basic
criterion for comparison among the players was, to what extent a player’s moves
deviate from the computer’s moves. More precisely, we considered the average
deviation between computer's evaluations of moves played by the human and machine-preferred
moves. Also, we designed a method for assessing the complexity of a position,
in order to take into account the different playing styles of the players and
the difficulty of the positions they faced.
Many people found the results surprising. For example, Capablanca emerged as
the top scorer according to the main criterion in that analysis. One reservation
regarding these results was: Was Crafty, whose rating is no more than 2620,
sufficiently strong for such a demanding comparison? What if a stronger chess
program was used? Here we present some results from two further studies
(Guid et al. 2008; Guid and Bratko 2011) that are relevant to these questions.
These results, which include analyses with programs SHREDER,
RYBKA 2 and RYBKA 3, can be summarised
as follows:
-
In a repeat of our earlier analysis of chess champions, the results obtained
with one of the strongest programs, RYBKA 3, were
qualitatively very similar to the results obtained with CRAFTY.
-
The rough ranking of the players according to different programs is quite
stable. More precisely, given two chess players, either all the programs
unanimously rank one player to be clearly stronger than the other, or all
the programs assess their strengths to be similar.
-
In order to obtain a sensible ranking of the players according to the criterion
considered, it is not necessary to use a computer that is stronger than
the players themselves. Interestingly, even considerably weaker programs
tend to consistently produce similar rankings.
Introduction
The aim of our computer
analysis of individual moves in World Chess Championship matches was to
assess as objectively as possible one aspect of the playing strength of chess
players of different eras. The open-source chess program CRAFTY
was used. Among several criteria considered, the basic criterion for comparison
among players was the average deviation between computer's evaluations of moves
played by humans and machine-preferred moves.
Subsequent statistical analysis
(2008) demonstrated that, at least for pairs of the players
whose scores differed significantly, it is not very likely that the
relative rankings of the champions according to the criterion considered would
change if (1) a stronger chess program was used, or (2) if the program would
search more deeply, or (3) larger sets of positions were available for the analysis.
In current article, we further verify propositions (1) and (2) empirically by
applying three chess programs stronger than CRAFTY for the same type of computer
analysis of the players’ skills.
We also repeated our earlier
analysis with the program CRAFTY of World Chess Champions with currently one
of the strongest chess programs, RYBKA 3, and obtained qualitatively
very similar results as with CRAFTY (click if you're too curious and want
to see the results of the computer analysis with RYBKA 3 immediately).
Mission impossible?
Establishing computer programs for estimating chess players' skills may seem
impossible, since it is well known that both programs' evaluations and programs’
decisions tend to change as the depth of search increases. Moreover, different
programs typically assign different evaluations to a given position, even when
using the same depth of search. Which program is therefore to be the most trusted
one as the estimator: the strongest one in terms of the programs’ competition
strength, or perhaps the one that is most equally unfair to all the players
that are a subject of evaluation?
 |
| Program |
Evaluation |
| Chessmaster 10 |
0.15 |
| Crafts 19.19 |
0.20 |
| Crafty 20.14 |
0.08 |
| Deep Shredder 10 |
-0.35 |
| Deep Shredder 11 |
0.00 |
| Fritz 6 |
-0.19 |
| Fritz 11 |
0.07 |
| Rybka 2.2n2 |
-0.01 |
| Rybka 3 |
-0.26 |
| Zappa 1.1 |
0.13 |
|
Lasker-Capablanca, St. Petersburg 1914, position after White’s 12th move.
The table on the right shows backed-up heuristic evaluations obtained by various
chess programs, using 12-ply search.
All the above stated issues seem like an obstacle on the way to establishing
heuristic-search based methods as competent estimators of human skill levels,
especially in complex games such as chess.
In the present research, we provide an analysis of the differences between
heuristic-search based programs in estimating chess skill, using a similar approach
as in our earlier studies (2006-2008). We are particularly interested in analysing
the behaviour of different chess programs, and to what extent the scores and
the rankings of the players are preserved at different depths of search. Since
the strength of computer-chess programs increases by search depth, the preservation
of the rankings at different search depths would therefore suggest not only
that the same rankings would have been obtained by searching more deeply, but
also that using stronger chess programs would probably not affect the results
significantly.
In the sequel, we present some of our results from the following scientific
papers:
- M. Guid and I. Bratko. Using Heuristic-Search Based Engines for Estimating
Human Skill at Chess. ICGA Journal, Vol. 34, No. 2, pp. 71-81, 2011.
- M. Guid, A. Pérez and I. Bratko. How Trustworthy is CRAFTY's
Analysis of World Chess Champions? ICGA Journal, Vol. 31, No. 3, pp. 131-144,
2008.
An interested reader will find the links to both papers below.
To avoid possible misinterpretation of the presented work, it should be noted
that these articles are not concerned with the question of how appropriate the
particular measure of the playing strength (deviation of player's moves from
computer-preferred moves, using a sufficiently large sample of positions for
the computer analysis) is as a criterion for comparing chess players' ability
in general. It is only one of many sensible criteria of this kind. Nevertheless,
we believe that the relatively good preservation of the rankings at different
levels of search using various programs of different competition strengths may
represent a solid ground on the way to discover increasingly better methods
for establishing heuristic-search based computer programs as reliable estimators
of skill levels in game playing.
What if a WEAKER program than (12-ply) Crafty was used for the computer
analysis of the champions?
Various discussions about our 2006 article
took place at different popular blogs and forums across the internet, and Chessbase
soon published some interesting responses
by various readers from all over the world, including some by scientists. A
frequent comment by the readers could be summarised as: "A very interesting
study, but it has a flaw in that program CRAFTY, of which
the rating is only about 2620, was used to analyse the performance of players
stronger than CRAFTY. For this reason the results cannot
be useful." Some readers speculated further that the program will
give a better ranking to players that have a similar strength to the program
itself.
The main two objections by the readers to the used methodology were: (1) the
program used for analysis was too weak, and (2) the search depth of 12 plies
performed by the program was too shallow.
We addressed these objections in order to assess how reliable CRAFTY
(or, by extrapolation, any other fallible chess program) is as a tool for comparison
of chess players, using the suggested methodology. In particular, we were interested
in observing to what extent the scores and the rankings of the players are preserved
at different depths of search. We first observed CRAFTY's
rankings of the champions at lower search depths.
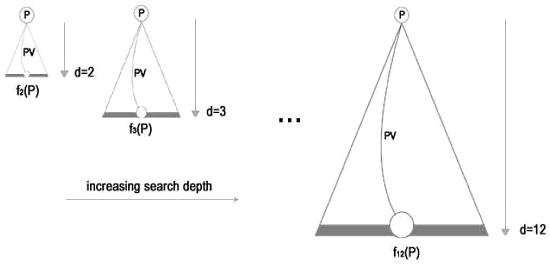
In each position, we performed searches to depths ranging from 2 to 12
plies extended with quiescence search to ensure stable static evaluations. Backed-up
evaluations of each of these searches were used for analysis. PV stands for
principal variation.
Searches to various depths were conducted (including quiescence search to obtain
stable evaluations). Then the scores obtained by the program are the average
differences between computer evaluations of the players' choices of moves and
the computer's choices at each particular search depth. Based on players' scores,
rankings of the players are obtained in such a way that a lower score results
in a better ranking. Additional constraints and other details about the methodology
used are described in our ICGA Journal paper (2008).
The computer analysis was based on the evaluation of the games played by the
chess champions in the classical World Chess Championship matches between 1886
(Steinitz-Zukertort) and 2006 (Kramnik-Topalov). The following fourteen champions
were therefore included in the analysis: Steinitz, Lasker, Capablanca, Alekhine,
Euwe, Botvinnik, Smyslov, Tal, Petrosian, Spassky, Fischer, Karpov, Kasparov,
and Kramnik.
Our results show, possibly surprisingly, that at least
for the players whose scores differ sufficiently from the others the ranking
remains preserved, even at very shallow search depths.
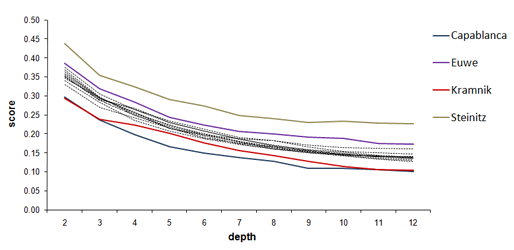
CRAFTY's scores (average deviations between the evaluations
of played moves and best-evaluated moves according to CRAFTY)
of each "classical" world champion (1886-2006) at different depths
of search. Highlighted are the scores of Capablanca (bottom curve), Kramnik,
Euwe and Steinitz (top curve).
Some champions whose rankings significantly deviate from the others were identified:
Capablanca, Euwe, and Steinitz. Their relative rankings among all the champions
were preserved at each level of search. The stability of their rankings was
further supported by the statistical analysis of the results and by the fact
that Capablanca had the best score in 95% of all the subset-depth combinations
in 100 samples consisting of 500 randomly chosen positions. As we did in our
study, this result should be interpreted in the light of Capablanca's playing
style that tended towards low complexity positions.
Using stronger programs for the analysis
To study whether different heuristic-search based programs can be used as estimators
of skill levels, we will now focus on these three players and check whether
other chess programs rank them in the same order as CRAFTY
did. We will observe variations with depth of average differences between player’s
and program’s decisions on a large subset of randomly chosen positions from
the World Chess Championship matches using three chess programs stronger than
CRAFTY, namely: SHREDDER, RYBKA
2, and RYBKA 3.
All positions for the analysis were taken from classical World Chess Championship
matches (1886-2006). Besides analysing the moves of the three players, we also
randomly picked more than 20,000 positions of the rest of the players as a control
group.
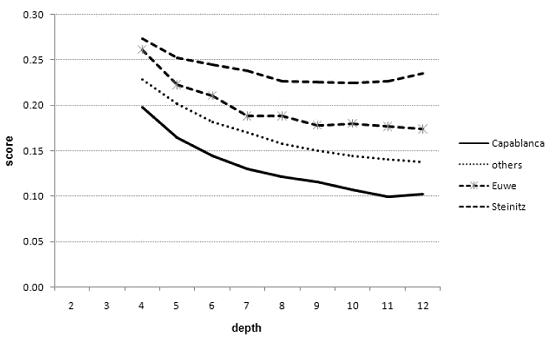
The scores of Capablanca (bottom curve), the control group, Euwe, and Steinitz
(top curve), obtained on a large subset of games from World Chess Champion matches,
using SHREDDER.
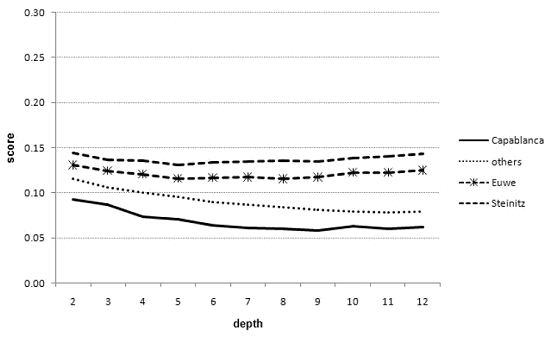
The scores of Capablanca (bottom curve), the control group, Euwe, and Steinitz
(top curve), obtained on a large subset of games from World Chess Champion matches,
using RYBKA 2.
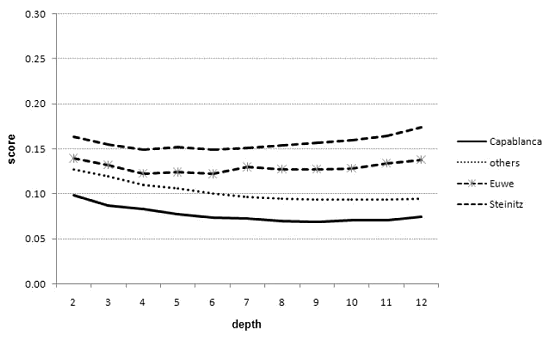
The scores of Capablanca (bottom curve), the control group, Euwe, and Steinitz
(top curve), obtained on a large subset of games from World Chess Champion matches,
using RYBKA 3.
The relative ranking of Capablanca, Euwe, Steinitz, and the players in the
control group are preserved at all depths using any of the programs at any level
of search. These experimental findings reject possible speculations that using
chess programs stronger than CRAFTY for the analysis
could lead to completely different results, and that Capablanca’s result is
merely a consequence of his style being similar to CRAFTY’s
style. We also view these results as another confirmation that in order to obtain
a sensible ranking of the players, it is not necessary to use a computer that
is stronger than the players themselves.
Computer analysis of World Chess Champions revisited with RYBKA
3
We present the results of computer analysis of World Chess Champions obtained
by RYBKA 3. We analysed the same matches as in (2008),
in order to make the comparison of the results obtained by chess programs CRAFTY
and RYBKA 3 as relevant as possible. That is, games for
the title of World Chess Champion, in which the fourteen classic World Champions
(from Steinitz to Kramnik) contended for or were defending the title, were selected
for the analysis. The details of the methodology are given in the paper (2011).
Searches to 11 and 12 plies were omitted in order to shorten the computational
time required for such an extensive analysis.
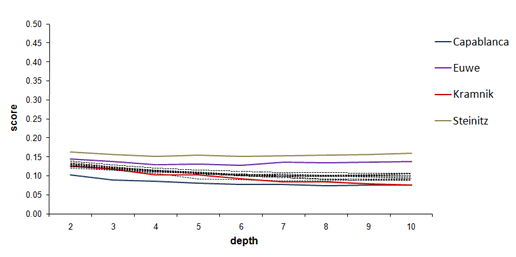
RYBKA's scores (average deviations between the evaluations
of played moves and best-evaluated moves according to RYBKA
3) of each "classical" world champion (from 1886 to 2006) at different
depths of search. Highlighted are the scores of Capablanca (bottom curve), Kramnik,
Euwe and Steinitz (top curve). Based on players' scores, rankings of the players
are obtained in such a way that a lower score results in a better ranking.
Let us take a closer view:
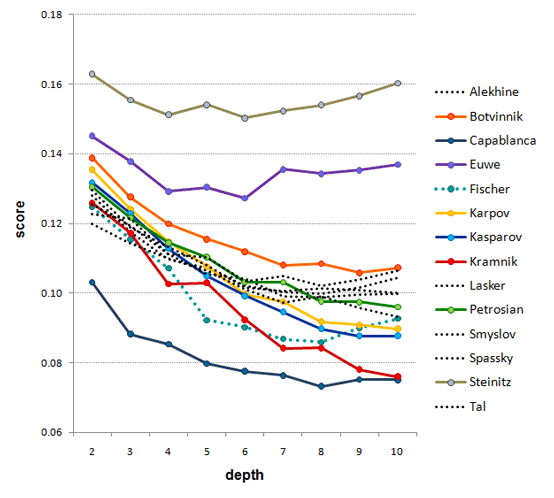
A closer view: the scores of the champions obtained by chess program RYBKA
3 at various depths of search. For almost all depths it holds that rank(Capablanca)
< rank(Kramnik) < rank (Kasparov) < rank (Karpov) < rank(Petrosian) < rank(Botvinnik)
< rank(Euwe) < rank(Steinitz).
The results closely resemble the ones obtained by CRAFTY
(2008). Again the rankings stay the same for almost all
depths: rank(Capablanca) < rank(Kramnik) < rank (Karpov, Kasparov) <
rank(Petrosian) < rank(Botvinnik) < rank(Euwe) < rank(Steinitz). However,
there are nevertheless some obvious differences between the results obtained
by the two programs. Firstly, CRAFTY ranked Karpov better
than Kasparov at all depths: just the opposite holds for RYBKA
3. Nevertheless, the scores of both (and also many other) players are rather
similar to each other.
Secondly, the performance of Fischer as seen by RYBKA
3 is significantly better in comparison with the results obtained by CRAFTY.
This finding is associated with the following (so far unanswered) question:
Does a program's style of play exhibit preference for the styles of any particular
players? The comparison of the results of computer analysis of the champions
obtained by CRAFTY and RYBKA 3
suggests that a program’s style of play may affect the rankings, but only to
a limited extent.
The meaning of the scores
One frequent question by the readers was associated with the meaning of the
players’ scores obtained by the program. A typical misinterpretation of their
meaning went like this: "For every 8 moves on average, CRAFTY
expects to gain an advantage of one extra pawn over Kasparov." We would like
to emphasize here that the scores obtained by the program only measure the average
differences between the players' choices of move and the computer's choice.
However, as the analysis shows these scores that are relative to the computer
used, have good chances to produce sensible rankings of the players.
The experimental results not only confirm that the scores are not invariable
for the same program at different depths of search, the scores also differ significantly
when using different programs. This is most clearly seen in the following graph,
where average scores of all the players, obtained on the same large subset of
games from World Chess Champion matches, are shown for the three programs, and
compared to average scores of all the players according to CRAFTY.
While the scores of SHREDDER are very similar to the
scores of CRAFTY, the scores of the two RYBKAs
differ considerably from those of the other two programs.
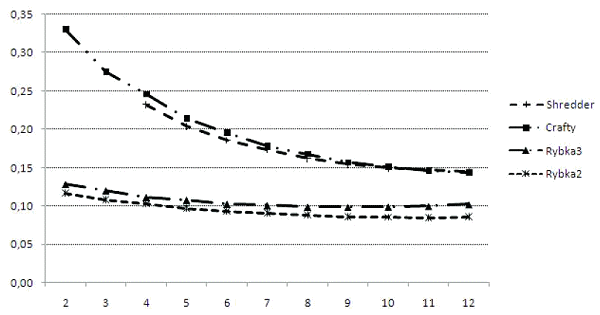
Comparison of average scores of all the players (including the ones in
the control group), obtained
by CRAFTY, SHREDDER, RYBKA
2, and RYBKA 3.
In the paper (2011), we provided the following explanation
regarding the magnitude of the scores with respect to the search depth. The
decreasing tendency of the scores with an increasing search depth (typical
at the shallower search depths) is a consequence of increasingly better choices
by the program. At higher search depths, however, the higher cost of not
choosing the best move according to the program may even lead to increased
scores due to the monotonicity property of heuristic evaluation functions.
That is, in won positions programs' evaluations tend to increase monotonically
with depth of search.
Where to go on from here?
Our approach to estimating skill levels is aimed at assessing the quality of
play regardless of the game score, and assumes using fallible estimators
(as opposed to infallible estimator such as chess tablebases). Since our paper
in 2006, several related and interesting scientific works
emerged. Haworth (2007) defined a mapping of the apparent player’s skill into
a Referent Agent Space, using a stochastic agent and a Bayesian inference method.
The results of the experimental analysis with this approach (Di Fatta, Haworth,
and Regan, 2009; Haworth, Regan, and Di Fatta, 2010; Regan and Haworth, 2011)
showed that the inferred probability distributions of the apparent skills are
able to discriminate players’ performances in different Elo ranges. These results
further speak in favour of a possibility to estimate human skills based on computer
heuristic evaluation. Full references of these papers are given below.
Both of these approaches to estimating skill levels in complex games have something
in common, besides that they are based on computer analysis of player’s actions:
they both assume (implicitly or explicitly) that average differences in computer
evaluations between the player’s moves and the computer’s moves provide a solid
ground for sensible benchmarking of the players, when a sufficiently large amount
of data for the analysis is available. That is, regardless of how this measure
is further refined to take into account the full context of the player’s decisions,
these average differences alone have good chances as rather stable performance
measures, even when using different programs as estimators of the players’ skills.
A remarkable amount of computation for a similar computer analysis of chess
champions was performed by Charles Sullivan. According to the author, for 24
hours a day for 15 months (from February 2007 through May 2008), 12 computing
threads (on three Intel quad-core Q6600 computers running at 3.0 GHz) analyzed
the games of the World Champions. Entire playing careers were analyzed - in
all, 617,446 positions from 18,785 games were processed. The results are published
at Truechess.com.
The author considers "Best 10-Year Period" statistics to be useful
for selecting "the greatest chessplayer of all time." His obtained
rankings were somewhat different from ours. However, these results cannot be
directly compared because his analysis included ALL the games played, but limited
to the best 10-year period. It should also be noted that in his analysis, the
amount of computation per analysed position was limited by time and not by depth.
Thus, the average differences between the players' choices and the computer's
choices in Sullivan's analysis were obtained at different search depths and
may not be directly comparable, due to the monotonicity property of heuristic
evaluation functions (for a detailed explanation refer to Matej Guid's Ph.D.
Thesis, Chapter 8.5.1). We strongly recommend using fixed search depth
for this type of computer analysis of chess games.
One of the important (and still not completely resolved) issues is: How
to take into account the differences between players in the average difficulty
of the positions encountered in their games? In 2006,
we devised a heuristic-search based method to assess average difficulty of positions
used for estimating the champions’ performance and presented the results of
applying this method in order to compare chess players of different playing
styles. Those results suggested that Capablanca’s outstanding score in terms
of low average differences in computer evaluations between the player’s moves
and the computer’s moves should be interpreted in the light of his playing style
that tended towards low complexity positions. However, we believe that further
work on the above question is required.
The authors
Matej Guid has received his Ph.D. in computer science
at the University of Ljubljana, Slovenia. His research interest include
computer game-playing, automated explanation and tutoring systems, heuristic
search, and argument-based machine learning. Some of his scientific
works, including the Ph.D. thesis titled Search and Knowledge for
Human and Machine Problem Solving, are available on Matej's Research
page. Chess has been one of Matej's favourite hobbies since his
childhood. He was also a junior champion of Slovenia a couple of times,
and holds the title of FIDE master. |
|
 |
Ivan Bratko is professor of computer science at University
of Ljubljana, Slovenia. He is head of Artificial intelligence Laboratory,
Faculty of Computer and Information Science of Ljubljana University, and
has conducted research in machine learning, knowledge-based systems, qualitative
modelling, intelligent robotics, heuristic programming and computer chess
(do you know the famous Bratko-Kopec
test?). Professor Bratko has published over 200 scientific papers
and a number of books, including the best-selling Prolog
Programming for Artificial Intelligence. Chess is one of his favourite
hobbies. |
References
- M. Guid and I. Bratko. Using
Heuristic-Search Based Engines for Estimating Human Skill at Chess. ICGA
Journal, Vol. 34, No. 2, pp. 71-81, 2011.
- M. Guid, A. Pérez and I. Bratko. How
Trustworthy is CRAFTY's Analysis of World Chess Champions? ICGA Journal,
Vol. 31, No. 3, pp. 131-144, 2008.
- M. Guid and I. Bratko. Computer
Analysis of World Chess Champions. ICGA Journal, Vol. 29, No. 2, pp. 65-73,
2006.
- M. Guid. Search
and Knowledge for Human and Machine Problem Solving. Ph.D. Thesis, University
of Ljubljana, 2010.
- Chessbase: Computers
choose: who was the strongest player? 30.10.2006.
- Chessbase (reader's feedback): Computer
analysis of world champions. 2.11.2006.
- G. Haworth. Gentlemen, stop your engines! ICGA Journal, Vol. 30, No. 3,
pp. 150–156, 2007.
- Di Fatta, G., Haworth, G., and Regan, K. Skill rating by Bayesian inference.
CIDM, pp. 89–94, 2009.
- Haworth, G., Regan, K., and Di Fatta, G. Performance and Prediction: Bayesian
Modelling of Fallible Choice in Chess. Advances in Computers Games, Vol. 6048
of Lecture Notes in Computer Science, pp. 99–110, Springer, 2010.
- K. Regan and G. Haworth. Intrinsic chess ratings. In Proceedings of AAAI
2011, San Francisco, 2011.
- C. Sullivan. Truechess.com
Compares the Champions. 2008.
Copyright
Guid/Bratko/ChessBase























