







ChessBase 17 - Mega package - Edition 2024
It is the program of choice for anyone who loves the game and wants to know more about it. Start your personal success story with ChessBase and enjoy the game even more.
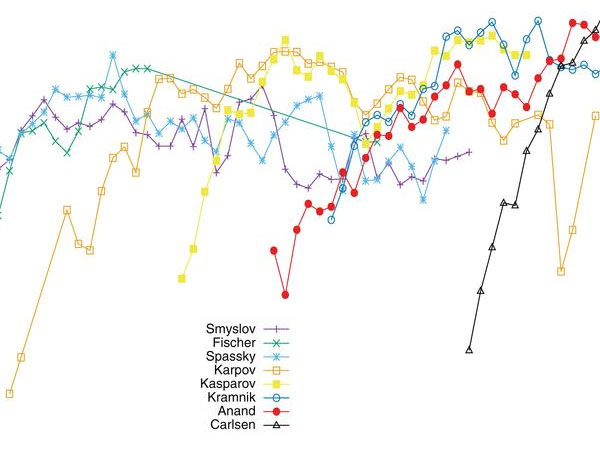
The Elo rating system in chess, well known to all of us, is based on the results of players against each other. Designed by the Hungarian physics professor and chess master Árpád Imre Élo in 1970 the system is used to predict the probability of rated players winning or losing their games against another rated players. If a player performs better or worse than predicted then rating points are added to or deducted from his rating. However, the Elo system does not take into account the the quality of the moves played during a game and is therefore unable to reliably rank players who have played at different periods in history.
Now computer scientist and AI researcher Jean-Marc Alliot of the Institut de Recherche en Informatique de Toulouse has come up with a new system (and reported on it in the journal of the International Computer Games Association) that does exactly that: rank players by evaluating the quality of their actual moves. He does this by comparing the moves of World Champions with those of a strong chess engine – the program Stockfish running on a supercomputer. The assumption is that the engine is executing almost perfect moves.
Alliot has evaluated 26,000 games played by World Champions since Steinitz, estimating the probability of their making a mistake – and the magnitude of the mistake – for each position in their games. From this he derived a probabilistic model for each player, and used it to compute the win/draw/lose probability for any given match between any two players. The predictions, he says, have proven not only to be extremely close to the results from actual encounters between the players, but they also fare better than those based on Elo scores. The results, he claims, demonstrate that the level of chess players has been steadily increasing. The current world champion, Magnus Carlsen, tops the list, while Bobby Fischer is third.
Here are predictions of game results between the different world champions in their best year:
| Ca | Kr | Fi | Ka | An | Kh | Sm | Pe | Kp | Ks | |
| Carlsen | 52 | 54 | 54 | 57 | 58 | 57 | 58 | 56 | 60 | |
| Kramnik | 49 | 52 | 52 | 55 | 56 | 56 | 57 | 55 | 59 | |
| Fischer | 47 | 49 | 51 | 53 | 57 | 56 | 57 | 56 | 59 | |
| Kasparov | 47 | 49 | 50 | 53 | 54 | 54 | 54 | 53 | 57 | |
| Anand | 44 | 46 | 48 | 48 | 54 | 52 | 53 | 53 | 57 | |
| Khalifman | 43 | 45 | 44 | 47 | 47 | 50 | 51 | 52 | 53 | |
| Smyslov | 43 | 45 | 45 | 47 | 49 | 51 | 50 | 51 | 53 | |
| Petrosian | 43 | 44 | 45 | 47 | 49 | 50 | 51 | 52 | 53 | |
| Karpov | 44 | 46 | 45 | 48 | 48 | 49 | 50 | 49 | 51 | |
| Kasimdzhanov | 41 | 43 | 42 | 45 | 45 | 48 | 48 | 48 | 50 |
Under current conditions, Alliot feels, this new ranking method cannot immediately replace the Elo system, which is easier to set up and implement. However, increases in computing power will make it possible to extend the new method to an ever-growing pool of players in the near future.
Read the full detailed paper published by Jean-Marc Alliot in the ICGA Journal, Volume 39 -1, April 2017. Mathematically proficient readers are welcome to comment on his method and his results.




| Advertising |










